안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다.
오늘 알아볼 내용은 강화 학습을 이용해 'CartPole'게임을 학습시키는 것입니다.
우선 'CartPole'게임에 대해 알아보도록 하겠습니다. 'CartPole'게임은 아래 그림과 같이 막대기를 쓰러지지 않도록 좌우로 움직이면서 균형을 잡는 게임입니다. 이는 아래 openai 링크에 들어가면 자세히 설명이 되어있습니다. 뿐만 아니라 openai에서는 이 게임을 이용할 수 있게 오픈소스로 풀어놨으니 맘껏 사용하시면 됩니다.
https://gym.openai.com/envs/CartPole-v1/
Gym: A toolkit for developing and comparing reinforcement learning algorithms
Open source interface to reinforcement learning tasks. The gym library provides an easy-to-use suite of reinforcement learning tasks. import gym env = gym.make("CartPole-v1") observation = env.reset() for _ in range(1000): env.render() action = env.action_
gym.openai.com

여기서 우리가 사용할 알고리즘은 강화 학습이라는 알고리즘입니다. 강화 학습의 정의는 다음과 같습니다.
강화 학습(Reinforcement learning) : 기계 학습의 한 영역이다. 행동심리학에서 영감을 받았으며, 어떤 환경 안에서 정의된 에이전트가 현재의 상태를 인식하여, 선택 가능한 행동들 중 보상을 최대화하는 행동 혹은 행동 순서를 선택하는 방법이다.
한마디로 강화학습은 알고리즘이 어떠한 상태(state)에서 특정 행동(action)을 취했을 때 결괏값을 가지고 점수(reward)를 다르게 주어 가장 효과적인 행동을 찾아가는 학습 알고리즘입니다. 우리는 이러한 강화 학습 알고리즘 중에서도 DQN알고리즘을 사용할 것입니다. 자세한 내용은 다음에 다루도록 하고 이번 시간에는 "이 알고리즘이 알파고에 쓰였던 알고리즘이다."정도만 알도록 하겠습니다.
그러면 지금부터는 이러한 강화학습(Reinforcement Learning, DQN) 알고리즘을 이용해 'CartPole'게임을 학습시키는 것을 알아보도록 하겠습니다.
우선 아래와 같이 이번 학습에 필요한 기본적인 파일들을 설치 해줍니다. 여기서는 tensor flow, gym, keras를 설치해줍니다.
!pip install tesorflow == 2.3.0
!pip install gym
!pip install keras
!pip install keras-rl2
그다음 아래와 같이 필수적인 라이브러리를 불러와줍니다. 여기서 몇 가지에 대해 알아보도록 하겠습니다.
- gym : 게임 환경을 불러올수 있도록 하는 라이브러리
- Dense : 인공신경망의 fully connected layer를 만들어주는 라이브러리
- Flatten : 추출된 주요 특징을 fully connected layer에 전달하기 위해 1차원 자료로 바꿔주는 layer 라이브러리
import gym
import random
import numpy as np
import tensorflow
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import Adam
from rl.agents import DQNAgent
from rl.policy import BoltzmannQPolicy
from rl.memory import SequentialMemory
이제 인공지능 모델을 만들어 주면 되는데 먼저 인공신경망 모델을 만들어줍니다. 저는 Flatten layer 1층, Dense layer 3층 이렇게 총 4층 layer를 만들어 주도록 하겠습니다. 아래 코드 중 model.add(Dense(24, activation = 'relu'))에서 24는 출력 뉴런수를, activation은 활성화 함수를 의미합니다. 각자 성능이 좋은 방향으로 알아서 설정을 해주면 됩니다.
def build_model(states, actions):
model = tensorflow.keras.Sequential()
model.add(Flatten(input_shape = (1, states)))
model.add(Dense(24, activation = 'relu'))
# 출력 뉴런수 24개, 활성화 함수 'relu'
model.add(Dense(24, activation = 'relu'))
model.add(Dense(actions, activation = 'linear'))
return model
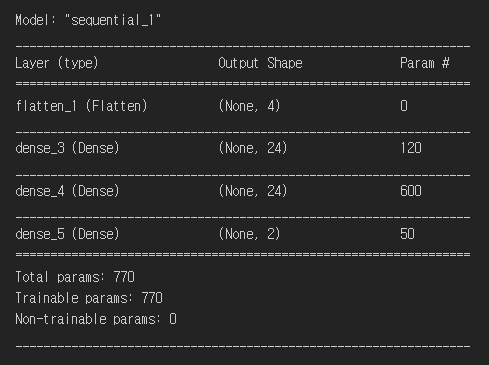
위에서 우리가 만든 모델을 확인해주면 아래와 같습니다. 우리의 order데로 Flatten layer 1층, Dense layer 3층 이렇게 총 4층 layer가 만들어진 것을 확인할 수 있었습니다.
model = build_model(states, actions)
model.summary()
그다음에는 이제 강화 학습 에이전트를 만들어주어야 합니다. 여기서 SequentialMemory의 최대길이는 10000으로 해줍니다.
- nb_steps_warmup : 파라미터가 너무 진동하는것을 방지하기 위해 예열(warmup)을 하는 작업
- target_model_update : 얼마나 자주 target model을 업데이트 할것인지(target_model_update>1=업데이트를 많이, target_model_update <1=업데이트를 적게)
def build_agent(model, actions):
policy = BoltzmannQPolicy()
memory = SequentialMemory(limit = 10000, window_length = 1)
dqn = DQNAgent(model = model, memory = memory, policy = policy,
nb_actions = actions, nb_steps_warmup = 10, target_model_update = 1e-2)
return dqn
# rl.agents.dqn.DQNAgent(model, policy=None, test_policy=None, enable_double_dqn=True, enable_dueling_network=False, dueling_type='avg')
# nb_steps(integer): Number of training steps to be performed.
# nb_steps_warmup: some schemes where the learning rate changes in a pre-determined way, to protect your oscillate parameters in the first time.
# target_model_update: 얼마나 자주 target model을 업데이트 할것인지(>1=업데이트를 많이, <1=업데이트를 적게)
마지막으로 dqn알고리즘을 정의해주고 fitting을 해주어 학습을 시켜주면 알고리즘이 완성됩니다. 여기서 Adam 알고리즘의 lr상수는 1e-3으로, metrics는 mae(mean absolute error)로 정의해줍니다. 또한 학습은 100000번 시켜줍니다.
dqn = build_agent(model, actions)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
dqn.fit(env, nb_steps=100000, visualize=False, verbose=1)
# compile(self, optimizer, metrics=[])/ mae(mean absolute error)
# fit(self, env, nb_steps, action_repetition=1, callbacks=None, verbose=1, visualize=False, nb_max_start_steps=0, start_step_policy=None, log_interval=10000, nb_max_episode_steps=None)
# verbose: By setting verbose 0, 1 or 2 you just say how do you want to 'see' the training progress for each epoch.
이 모델을 테스트 해주면 아래와 같이 아주 학습이 잘 되어 게임을 잘하는 것을 알 수 있습니다.
dqn.test(env, nb_episodes = 10, visualize = True)

만약 이렇게 학습된 weight값들을 저장하고 다음에 빠르게 불러와 사용하고 싶으면 아래 코드들을 이용하여 저장 및 불러오기가 가능합니다.
dqn.save_weights('dqn_weights.h5f', overwrite = True)
# weight값들을 저장dqn.load_weights('dqn_weights.h5f')
위의 코드들은 아래 제 github링크에 있으니 참고하시기 바랍니다.
https://github.com/CodingOpera/RL/blob/main/CartPole-v0.ipynb
GitHub - CodingOpera/RL
Contribute to CodingOpera/RL development by creating an account on GitHub.
github.com
오늘은 강화학습 DQN으로 CartPole게임 학습시키기에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이였습니다. 감사합니다.
'머신러닝' 카테고리의 다른 글
| 나이브 베이즈 분류 알고리즘(Naive Bayes Classifier Algorithm), 스팸메일 예측(Spam Mail) (0) | 2022.01.27 |
|---|---|
| 나이브 베이즈 분류 알고리즘(Naive Bayes Classifier Algorithm), 타이타닉 생존자 예측 (0) | 2022.01.27 |
| K-평균 알고리즘(K-means clustering algorithm) (0) | 2022.01.20 |
| Support Vector Machine(SVM) (0) | 2022.01.20 |
| 로지스틱 회귀(Logistic Regression) (2) | 2022.01.12 |