안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Conducter'입니다.
오늘 알아볼 내용은 나이브 베이즈 분류 알고리즘(Naive Bayes Classifier Algorithm)입니다.
혹시 이전 제 블로그를 보셔서 베이즈 정리에 대한 이론적인 부분을 아시는 분들은 바로 아래 스팸메일 예측 예시로 넘어가 시가 바랍니다.
나이브 베이즈 분류 알고리즘(Naive Bayes Classifier Algorithm) : 특성들 사이의 독립을 가정하는 베이즈 정리를 적용한 확률 분류기의 일종
베이즈 정리(Bayes’ theorem) :두 확률 변수의 사전 확률과 사후 확률사이의 관계를 나타내는 정리다. 베이즈 확률론 해석에 따르면 베이즈 정리는 사전 확률로부터 사후 확률을 구할 수 있다.
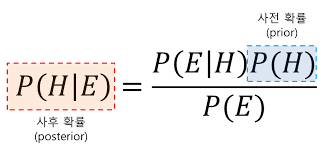
위의 베이즈 정리는 인공지능 분야에서 필수인 정리입니다. 이 정리는 사건이 일어나기 전의 확률인 사전 확률과 사건이 일어난 이후 확률인 사후 확률의 관계를 나타내는 공식입니다.
예를 들어
P(H) : 자기 자신이 부자인 확률
P(E) : 부모가 부자일 확률
P(E|H) : 자기 자신이 부자인 사람 중에서 부모가 부자인 확률
위 3가지 사전 확률을 알고 있으면 사후 확률 <P(H|E) : 부모가 부자인 사람 중 자기 자신이 부자인 확률>을 베이즈 정리를 통해 알 수 있습니다.(위 공식 참고)
그러면 지금부터는 간단한 예시를 통해 나이브 베이즈 분류 알고리즘(Naive Bayes Classifier Algorithm) 알아보도록 하겠습니다. 이번 예시는 스팸 메일(Spam Mail)을 예측하는 알고리즘 문제를 풀어보도록 하겠습니다. 이는 스팸 메일(Spam)고 정상적인 메일(Ham)의 예시들을 학습하고 스팸 메일 여부를 예측하는 문제입니다.
우선 기본적인 라이브러리를 불러와줍니다. 여기서 train_test_split는 train, test data를 분리해주는 함수이고 GaussianNB은 가우시안 함수를 통해 분류를 해주는 함수입니다. 추가적인 함수는 아래와 같습니다.
- CountVectorizer: 문서 집합에서 단어 토큰을 생성하고 각 단어의 수를 세어 BOW 인코딩 벡터를 만든다.
- MultinomialNB: 카운트 데이터(ex 문장에 나타난 단어의 횟수)에 적용 가능
- Pipeline: cross validated(교차 검증 가능한) 여러 가지 단계를 합쳐놓은 것
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
# CountVectorizer: 문서 집합에서 단어 토큰을 생성하고 각 단어의 수를 세어 BOW 인코딩 벡터를 만든다.
from sklearn.naive_bayes import MultinomialNB
# MultinomialNB: 카운트 데이터(ex 문장에 나타난 단어의 횟수)에 적용가능
from sklearn.pipeline import Pipeline
# Pipeline: cross validated(교차 검증 가능한) 여러가지 단계를 합쳐놓은 것
그다음 spam.csv를 통해 예시 데이터를 가지고 옵니다. 추가적으로 스팸 메일 여부를 숫자로 이진화해주기 위해 apply함수를 사용하여 spam = 1, ham = 0으로 설정해줍니다. 참고로 spam.csv파일은 아래 첨부해 드렸습니다.
df = pd.read_csv('spam.csv')
df['spam'] = df['Category'].apply(lambda x: 1 if x=='spam' else 0)
# ham이면 0, spam이면 1
train_test_split를 이용하여 train data와 test data를 나눠줍니다.
X = df.Message; y = df.spam
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
Pipeline 함수를 통해 CountVectorizer()과 MultinomialNB()를 한 번에 적용해줍니다. 아래와 같이 Pipeline 함수는 참 간단하고 편리합니다.
clf = Pipeline([
('vectorizer', CountVectorizer()),
('nb', MultinomialNB())
])
이렇게 만들어진 clf모델에 fit를 해주고 score과 predict를 해줍니다. 저의 경우 score가 0.985로 상당히 잘 학습된 것을 확인할 수 있었습니다.
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
clf.predict(X_test)
오늘은 나이브 베이즈 분류 알고리즘(Naive Bayes Classifier Algorithm), 스팸메일 예측(Spam Mail)에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Conductor'였습니다. 감사합니다.
<출처 및 참고 : 위키백과, code basics>
'머신러닝' 카테고리의 다른 글
| 강화학습 DQN으로 CartPole게임 학습시키기 (0) | 2022.02.16 |
|---|---|
| 나이브 베이즈 분류 알고리즘(Naive Bayes Classifier Algorithm), 타이타닉 생존자 예측 (0) | 2022.01.27 |
| K-평균 알고리즘(K-means clustering algorithm) (0) | 2022.01.20 |
| Support Vector Machine(SVM) (0) | 2022.01.20 |
| 로지스틱 회귀(Logistic Regression) (2) | 2022.01.12 |