안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다.
오늘부터는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅하도록 하겠습니다. 제목처럼 진짜 핵심 내용을 쉽게 설명하는 것을 목표로 하고 있으니 자연어 처리(NLP)에 입문하고 싶은 분들은 많은 관심 부탁드립니다. 오늘 알아볼 내용은 '단어 수준 임베딩'입니다.
https://codingopera.tistory.com/58?category=1094804
2. 자연어처리 임베딩 종류 (BOW, TF-IDF, n-gram, PMI) [초등학생도 이해하는 자연어처리]
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 오늘부터는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅하도록 하겠습니다. 제목처럼
codingopera.tistory.com
이 글을 읽기 전에 위의 '임베딩 종류'글을 먼저 읽어보시길 추천 드립니다.
NPLM (Neural Probabilistic Language Model)
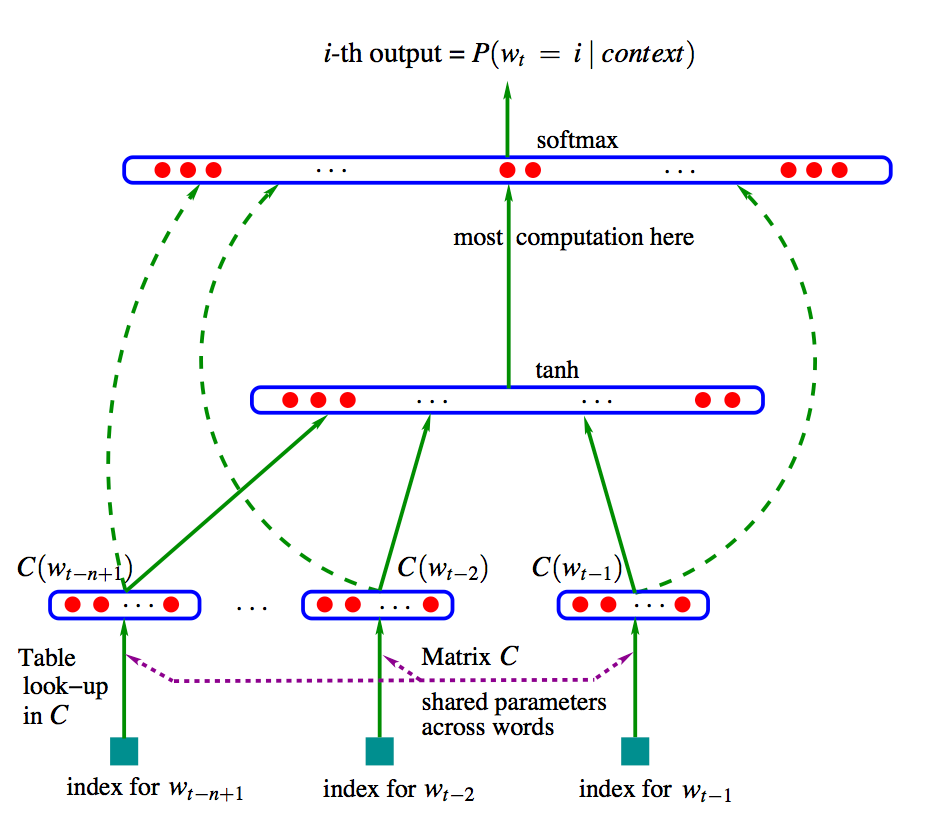
- NPLM : 'Neural Probabilistic Language Model'의 약자로 통계 기반 언어 모델의 문제점을 일부 극복한 모델
NPLM은 직전에 등장한 n-1개 단어(w_(t-n+1), ... , w_(t-1))를 통해 다음 단어 w_t를 맞추는 n-gram 언어모델입니다. NPLM의 학습과정은 위의 그림과 같습니다. 지금부터 하나씩 알아보도록 하겠습니다.
1. 단어벡터 x 만들기


원래 단어벡터는 원핫벡터인 'w'인데, 원핫벡터는 '0'이 많아 비 효율적입니다. 이러한 비 효율적인 벡터를 효율적인 벡터로 만들어주기 위해 참조 벡터 'C'를 사용합니다. 과정은 원핫벡터 w와 참조벡터 C를 내적해 새로운 효율적인 단어벡터 x를 위와같이 만들어줍니다.
이 과정을 '참조(lookup)'이라하고, 최종적인 결과는 참조벡터C의 한 행을 나타냅니다. C의 크기는 |V|*m으로 '|V|'는 어휘 집합 크기를, 'm'은 x의 차원수를 나타낸다.
2. 스코어 벡터 y

입력 x가 은닉층(hidden layer) H와 출력층(output layer) U를 통과하면, 위 y와 같은 스코어 벡터가 나옵니다. 이 때 H, U는 각각 은닉층과 출력층의 weight값이고 b, d는 bias값 입니다.
3. softmax 함수

위 2번에서 나온 스코어 벡터 y는 마지막으로 'softmax'함수를 거쳐 최종적인 output이 나옵니다. 즉 문맥단어 n+1개 (w_(t-1), ... , w_(t-n+1))를 이용해 타겟단어 w_t를 구합니다.
예를들어 [발, 없는, 말이]라는 단어들을 다음에 '천리'가 나오는 형태를 학습하는 과정에서 각 단어들은 비슷한 벡터 공간으로 모이게 됩니다. 즉 각 단어들의 벡터공간상 거리가 점점 가까워져, 의미가 서로 비슷해집니다.
4. 장단점
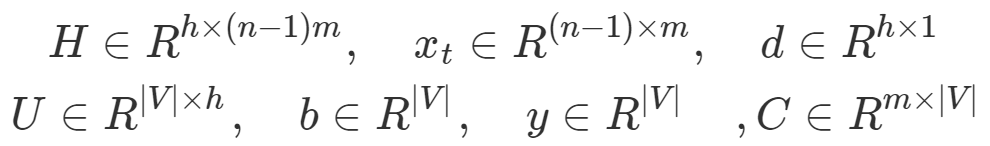
- 장점 : 기존의 원핫벡터가 아니라 밀집 벡터(Dense Vector)를 사용하기 때문에 벡터의 크기가 m으로 줄어 효율적이다.
- 단점 : 위와같이 학습 파라미터 수가 많다.
Word2Vec

- CBOW : 주변의 문맥 단어(context word)들을 가지고 타깃 단어(target word)하나를 맞추는 모델
- Skip-gram : 타깃 단어를 가지고 주변 문맥 단어들을 맞추는 모델
Word2Vec에는 CBOW와 Skip-gram 이렇게 두가지 과정이 있습니다. 예를들어 문맥단어가 4개라고 가정했을때, CBOW의 경우 입력값 4개(문맥 단어 4개)를 가지고 출력값(타깃 단어) 한개만을 유추하고, Skip-gram의 경우 입력값 1개(타깃 단어)를 가지고 출력값 4개(문맥 단어 4개) 유추합니다. 때문에 학습 난이도가 더 있는 'Skip-gram'이 그렇지 않은 'CBOW'보다 성능이 좋은 경향이 있습니다.
네거티브 샘플링(negative sampling)

Skip-gram 모델에서 타깃단어를 통해 주변 문맥 단어를 맞추는 과정은 softmax함수로 인해 계산량이 엄청납니다. 기본적으로 단어 집합속 단어 수는 보통 수십만개로 계산이 비효율적입니다. 그래서 고안된 방법이 '네거티브 샘플링(negative sampling)'입니다.
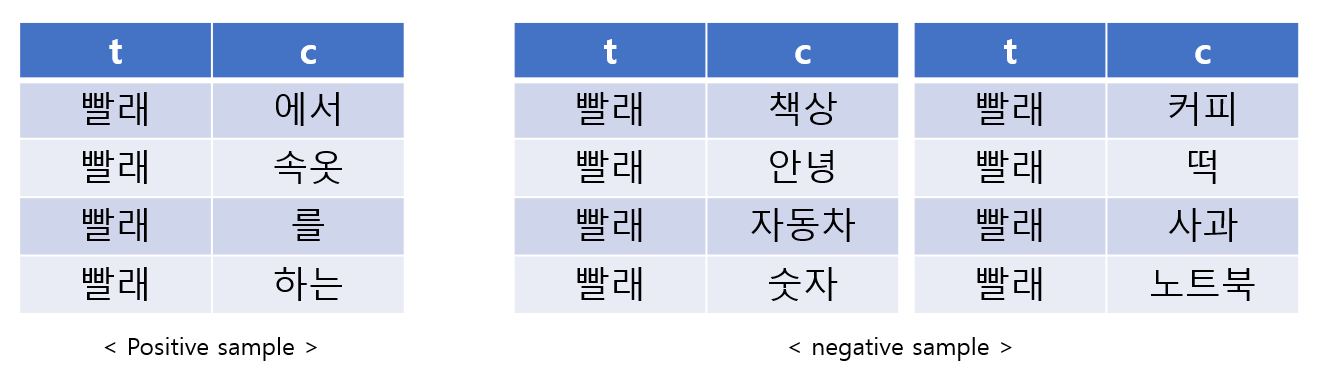
위와 같이 정답에 해당하는 데이터는 '포지티브 샘플링'이라 하고 오답에 해당하는 데이터를 '네거티브 샘플링'이라 합니다. 이렇게 되면 포지티브 샘플링 데이터 1개([빨래, 에서])와 k개의 네거티브 샘플링(if k=2: [빨래, 책상], [빨래, 커피])을 뽑아 포지티브 샘플링(+)인지, 네거티브 샘플링(-)인지 '이진 분류(binary classification)'하는 과정을 모델이 학습되어 연산이 효율이 좋습니다.
- 네거티브 샘플링 확률 : 말뭉치에서 자주 등장하지 않는 희귀한 단어가 네거티브 샘플로 더 잘 뽑힐 수 있도록 설계
여기서 f(w_i)는 해당 단어 'w_i'가 말뭉치에서 차지하는 비율을 나타냅니다.

- 서브샘플링(subsampling) 확률 : 고빈도의 자주쓰이는 단어를 등장 횟수만큼 모두 학습시키는 것이 비효율적이라고 생각하고 설계
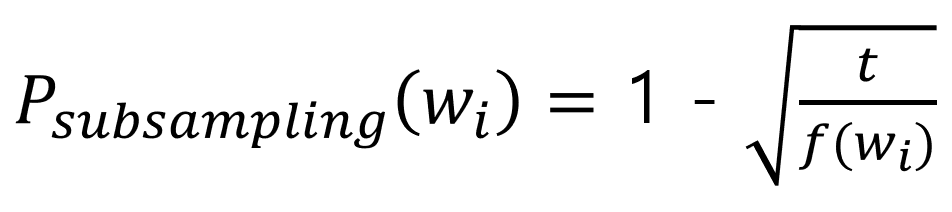

- U : 타깃 단어 집합
- V : 문맥 단어 집합
- |V| : 어휘 집합 크기
- d : 임베딩 차원수
Skip-gram에서는 LPLM과 달리 모델 파라미터가 U와 V 두개로 간단합니다. 이때 U는 타깃 단어 집합을, V는 문맥 단어 집합을 의미합니다. 예를들어 위 그림에서 '빨래'는 타깃 단어 u_t를, '속옷'은 문맥 단어 'v_t'를 의미합니다.


각각은 포지티브 샘플을 포지티브 샘플로, 네거티브 샘플을 네거티브 샘플로 판단할 확률입니다. 즉 모델의 성능을 높이려면 위에 나타낸 조건부확률을 최대화 해야합니다.
각각의 확률을 높이려면 포지티브 샘플의 경우 u, v의 내적값(연관성)을 키워야 되고, 네거티브 샘플의 경우 u, v의 내적값(연관성)을 줄여야 합니다.

위 수식은 Skip-gram 모델이 최대화 해야하는 로그우도 함수(log-likelihood function) 입니다. 모델 파라미터 theta를 한번 업데이트 할 때마다 1쌍의 포지티브 샘플과 k쌍의 네거티브 샘플을 학습한다는 의미입니다.
FastText
위에서본 Word2Vec의 가장 큰 문제점은 각 단어별로 별도의 단어 임베딩 벡터를 할당한다는 것입니다. 예를들어 '등산'과 '등산용품'은 다른 단어이기는 하지만 '등산'이라는 기본 단어에서 파생된 단어여서 뜻이 서로 비슷합니다. 그러나 Word2Vec의 경우 이 둘을 애초에 다른 임베딩 벡터로 간주합니다. 이런경우 단어수가 어형이나 형태에 따라 변형된 경우에도 다른 단어로 인식하여 연산량이 늘어나게 됩니다.



- FestText : 타깃 단어를 n-gram 형태로 나누어 학습하여 문자의 내재적 정보를 반영
이러한 문제점을 해결하기 위해 제시된 방법이 바로 'FastText'입니다. FastText의 경우 타깃 단어를 n-gram 형태로 나누어 학습하여 문자의 내재적 정보를 반영합니다. 예를들어 '시나브로'라는 단어를 3-gram으로 나누면 위와 같이 <시나, 시나브, 나브로, 브로> 그리고 원래 단어인 <시나브로> 이렇게 됩니다. 이 떄 '<, >'는 단어의 경계를 나타내주는 문자로 이 또한 단어의 일부분으로 취급합니다. 이러면 단어의 문자들이 윈도우수 만큼 나뉘어 연속적으로 학습되어 문자간 내재적 정보를 반영할 수 있습니다.


FastText역시 '포지티브 샘플'과 '네거티브 샘플'을 통해 학습을 진행합니다. Word2Vec과의 차이점은 위에서 보다싶이, 기존 타깃단어 u_t대신 n-gram으로 쪼개진 여러개의 타깃단어들을 이용해 학습을 진행하는 것입니다. 나머지는 Word2Vec과 동일 합니다.

잠재 의미 분석 (Latent Semantic Analysis, LSA)
- 잠재 의미 분석(LSA) : 단어-문서 행렬(Document-Term Matrix, DTM)과 같이 커다란 행렬에 차원 축소 방법의 일종인 특이값 분해(Singular Value Decomposition, SVD)를 이용해 데이터의 차원 수를 줄여 계산 효율성을 키우고 잠재 의미를 분석해 노이즈에 강한 모델을 만드는 분석 기법
이러한 잠재 의미 분석기법을 알아보기 전 특이값 분해(SVD)에 대해 먼저 알아보아야 합니다.
특이값 분해(Singular Value Decomposition, SVD)


특이값 분해란 위와 같이 특정 행렬을 직교행렬(orthogonal matrix)과 대각행렬(diagonal matrix)로 분해하는 방식을 의미합니다.
직교행렬(orthogonal matrix)

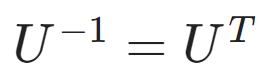


- 직교행렬 : 특정행렬과 그 행렬의 전치행렬을 곱했을때 단위행렬 I가 되는 행렬
- 전치행렬 : 특정 행렬의 행와 열을 행렬의 주대각선을 기준으로 맞바꿔진 행렬
- 단위행렬 : 행렬의 주대각선 부분이 '1'인 행렬. 어떠한 행렬과도 곱해도 그 행렬이 나오는 '항등원'
대각행렬(diagonal matrix)

- 대각행렬 : 행렬의 주대각선을 제외한 나머지 원소들이 모두 '0'인 행렬. 이 때 주대각선의 성분들은 서로 숫자가 달라도 됨.
truncated SVD
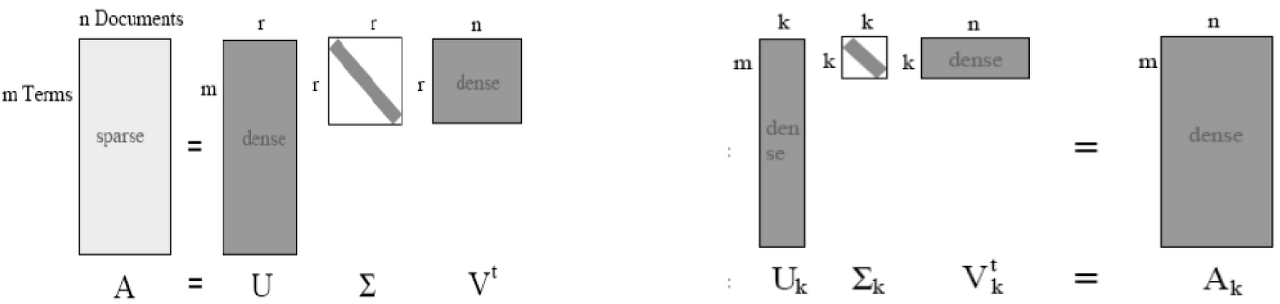
'truncated'은 한국어로 '끝을 잘라버린'이라는 뜻입니다. 따라서 truncated SVD는 일반적인 SVD에서 대각행렬을 임의의 kxk행렬로 잘라 값을 근사하는 방식입니다. 여기서 k는 하이퍼파라미로 모델러가 직접 조정해야되는 상수입니다.
LSA는 이렇게 truncated SVD를 이용하여 값을 근사해 계산효율도 올리고 행렬의 잠재의미를 분석해 노이즈를 제거하여 성능을 향상시킵니다.
GloVe (Global Word Vectors)
LSA와 Word2Vec의 문제점
- LSA : 카운트 기반으로 코퍼스의 전체적인 통계 정보를 고려. 때문에 단어의미 유추 작업(단어간 상관관계)에서 부정확(ex. 남자 - 여자)
- Word2Vec : 예측 기반으로 단어 간 유추 작업에는 LSA보다 뛰어나지만, 임베딩 벡터가 윈도우 크기 내에서만 주변 단어를 고려하기 때문에 코퍼스의 전체적인 통계 정보를 반영하지 못함
이러한 문제점들을 해결하기위해 'GloVe'는 LSA의 카운트 기반과 Word2Vec의 예측 기반을 모두 사용합니다.
동시 등장 확률 (Co-occurrence Probability)
- 중심단어 'i'가 나타났을 때 윈도우내에 주변단어 'j'가 나타날 확률

동시 등장 확률은 사용자가 정의한 윈도우내에 두 단어가 얼마의 확률로 같이 있느냐를 평가합니다. 예를들어 위와 같은 문장이 있을 때 윈도우가 2이라면, 중심단어 '사과'에 대한 주변단어 '둥글'은 (사과, 둥글) 수 / (사과) 수 = 1/2가 됩니다.


- A_ij : i와 j의 동시 등장 빈도
- U_i : i의 벡터
- V_j : j의 벡터
- b_i : i의 바이어스
- b_j : j의 바이어스
- |V| : 어휘 집합
GloVe의 목적은 '임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률이 되도록 만드는 것'입니다. 때문에 목적함수는 다음과 같이 됩니다. 여기서 바이어스는 임베딩의 품질을 높이기 위해 고안된 장치입니다.
Swivel (Submatrix-Wise Vector Embedding Learner)

Swivel (Submatrix-Wise Vector Embedding Learner)은 단어-문맥 행렬(word-context matrix)을 분해하는 'GloVe'와 다르게 'PMI'행렬을 분해합니다. 전체적인 과정은 GloVe와 비슷합니다.

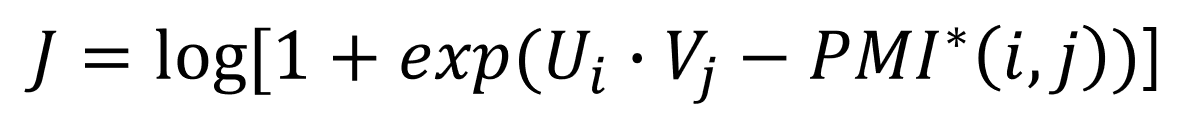
말뭉치에 겹치는 단어가 있는지 유무에 따라 위와 같이 목적함수가 달라집니다.
단어 임베딩을 평가하는 방법
1. 단어 유사도 평가
일련의 단어 쌍을 미리 구성한 후, 사람이 평가한 점수와 단어 벡터 간 코사인 유사도 사이의 상관관계를 계산해 단어 임베딩의 품질을 평가하는 방법
2. 단어 유추 평가
"'갑'과 '을'의 관계는 '병'과 '정'의 관계와 같다."는 의미론적 유추에서 단어 벡터 간 계산을 통해 "갑 - 을 + 정 = 병"이라는 질의에 '병'을 도출해낼 수 있는지를 평가
지금 까지 저희는 '단어 수준 임베딩 (NPLM, Word2Vec, FastText, 잠재 의미 분석, Glove, Swivel)'에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이었습니다. 감사합니다.
reference : ''한국어 임베딩"
'자연어처리(NLP)' 카테고리의 다른 글
| REFORMER: THE EFFICIENT TRANSFORMER (0) | 2023.05.17 |
|---|---|
| Big Bird: Transformers for Longer Sequences 논문 리뷰 (0) | 2023.05.13 |
| 2. 자연어처리 임베딩 종류 (BOW, TF-IDF, n-gram, PMI) [초등학생도 이해하는 자연어처리] (0) | 2023.04.08 |
| 1. 자연어처리 임베딩 [초등학생도 이해하는 자연어처리] (2) | 2023.04.07 |
| Rethinking Positional Encoding In Language Pre-training 논문 리뷰 (0) | 2023.03.05 |



