안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진짜 핵심 내용을 쉽게 설명하는 것을 목표로 하고 있으니 자연어 처리(NLP)에 입문하고 싶은 분들은 많은 관심 부탁드립니다. 이번 시간에 알아볼 내용은 'REFORMER: THE EFFICIENT TRANSFORMER' 논문입니다.
Introduction

- 원래의 NN 모델에서 연산의 중간 결과물(b1, b2)들을 연전파(back propagation) 전까지 따로 저장해야 함
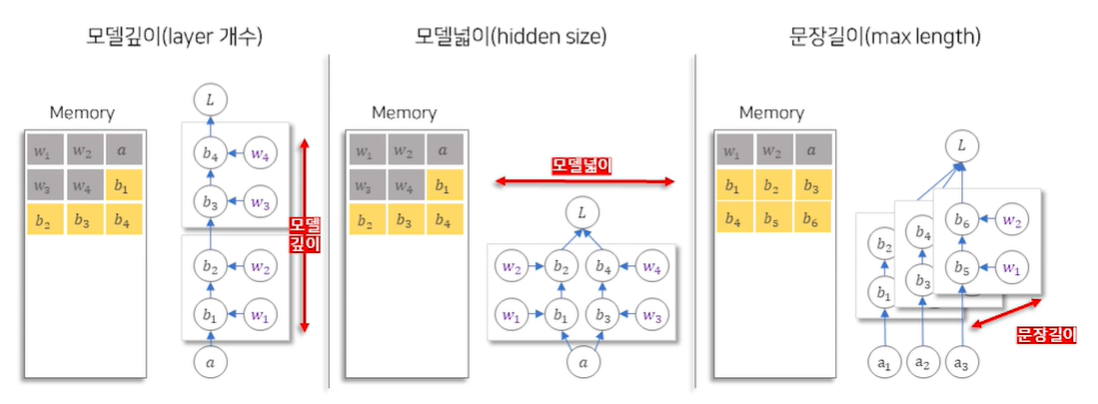
- 따라서 위와 같이 모델의 배치 사이즈, 싶이, 넓이, 문장 길이 등이 커지면 중간 결과물들의 크기가 증가하여 메모리도 증가함

위의 문제들을 해결하기 위해 이 논문에서는 다음과 같은 해결방안을 제시
- Attention Layer 개선 : 쓸모없는 Attention을 줄일 수 있도록 LSH Attention 적용(문장길이)
- Residual Block 개선 : 중간 값 저장 없이 역전파 할 수 있는 Reversible Network 구조 적용(모델깊이)
- Feedforward Layer 개선 : 계산하는 단위를 나누어 메모리를 사용할 수 있는 Chuncking 적용(모델넓이)
Locality-Sensitive Hashing Attention
기존의 attention은 모든 토큰들에 대해 attention을 수행했다면, 새로운 attention 메커니즘은 Locality-Sensitive Hashing
을 이용해 비슷한 일부 토큰들끼리만 attention을 수행함
Locality-Sensitive Hashing 이란?

- Hashing: 임의의 데이터를 길이가 고정된 값(해시값 또는 해시열쇠값)에 사상하는 것을 의미
- Locality-Sensitive Hashing(LSH): 원래 hashing을 한 값들은 서로 어떠한 연관성이 없어 hash함수에 의해 정확한 연산이 구현해야 되어 연산량이 많이 필요함. 이러한 문제점을 극복하기 위해 가까운 데이터끼리는 가까운 hash값을 갖도록 하는 Locality-Sensitive Hashing(LSH)가 등장. 이렇게 가까운 데이터끼리 비슷한 hash값을 갖게 되면 hash연산을 근사적으로 할 수 있음.
Angular LSH

- 이 논문에서는 LSH를 수행하기 위해 위와 같이 사상법(projection method)의 'angular LSH'를 사용함
- 단어 벡터들을 반지름이 1인 단위 구면에 사상함 (위에서 파랑, 주황, 적갈색 점은 각각 단어벡터를 의미)
- 각 사분면 별로 hash값을 1 ~ 4까지 부여
- 임의의 각도만큼 구면을 회전 (위 그림에서는 이해를 위해 사분면을 회전함)
LSH Attention

- 각 토큰의 Query, Key, Value를 생성 : Query, Key를 같은 layer에서 도출. 즉 Query == Key
- LSH 적용
- LSH의 버킷 인덱스가 같은 것끼리 정렬 : LSH의 원래 본질처럼 의미가 비슷한 것 끼리 가까이 배치
- 고정된 크기로 각각을 분절(Chunking) : 거리가 먼 것 끼리의 attention 수를 줄여 연산효율을 높임. 첫 번째 같은 버킷(같은 색)의 토큰들만 서로 attention가능. 두 번째 Query 토큰은 같은 구역 또는 바로 앞 구역의 Key에만 attention가능. 세 번째 자기 자신은 attention 하지 않음.
- Attention 적용
- 위 2, 3, 4 과정 계속 반복(Multi Round LSH Attention) : 몇 가지 제한을 통해 attention 연산수를 줄였으나, 이러한 attention 연산이 너무 제한적인 것을 방지하기 위해 과정을 반복.
Reversible Transformer
앞에서 언급했듯이 기존 Transformer의 Residual Block은 역전파를 위해 중간 결과를 따로 저장. 때문에 모델이 깊어져 layer가 많아질수록 메모리양이 증가. 이를 해결하기 위해 'Reversible Transformer'개념 도입.
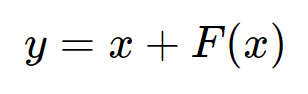
위의 식처럼 기존의 계산 블록은 입력 x를 이용해 출력 y를 구하는 구조. 반대로 출력 y를 이용해 입력 x는 구할 수 없음. 즉 역계산이 불가.
Forward Computation

Backward Computation


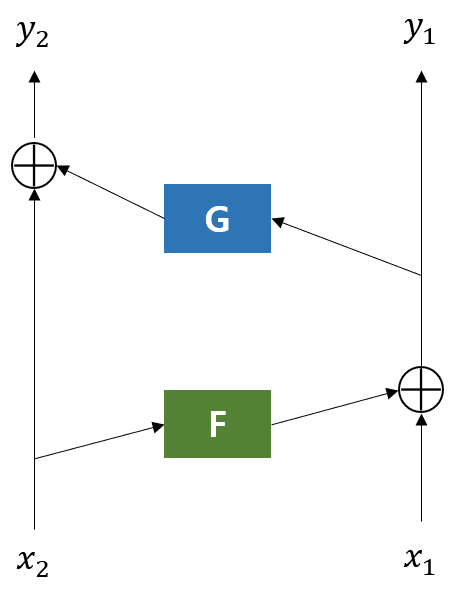
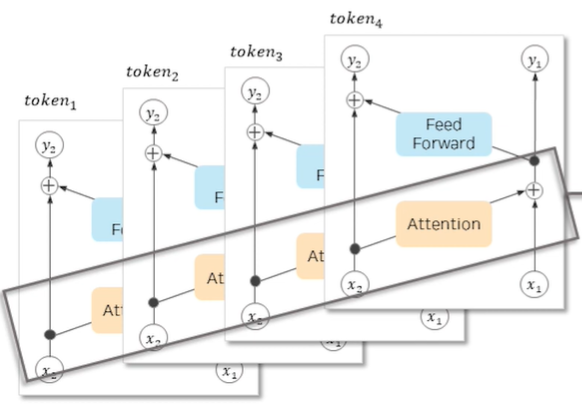
Reversible Transformer은 기존의 Transformer와 달리 입력값과 출력값을 각각 2개로 하는 트릭을 이용하여 출력값을 이용해서도 입력값을 역계산 할 수 있음. 때문에 back propagation시 중간 계산값을 저장할 필요가 없어 메모리 필요 용량이 줄어듦.
- 입력값 x를 복사하여 x1, x2로 구성, Reversible Network를 통과한 결괏값 y1, y2는 평균하여 y로 변경
- 출력값 y1, y2와 출력 Gradient y1 bar, y2 bar로 입력값 x1, x2와 입력 Gradient x1 bar, x2 bar를 추출
- 중간결과물 저장 없이 back propagation 계산

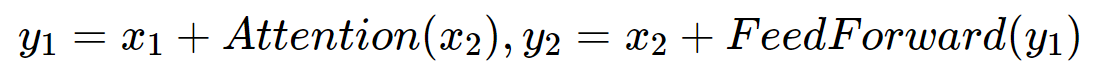
Chuncking
- Attention layer의 경우 각각의 토큰들은 각각의 positional encoding을 가지고 있기 때문에 데이터를 모두 한 번에 계산해야함 -> 때문에 메모리가 커짐
- FeedForward layer의 경우 Attention layer와 달리 이미 벡터가 positional 정보를 가지고 있기 때문에(Attention layer를 이미 거쳤기 때문) 데이터를 모두 한번에 계산할 필요가 없음 -> 때문에 이를 분절(Chuncking)하여 메모리를 줄임
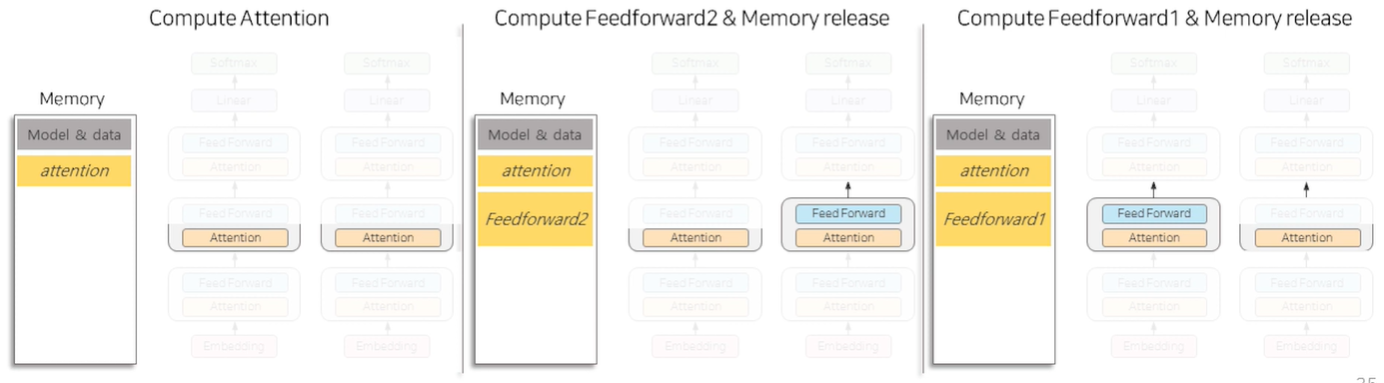
위와 같이 Attention layer를 병렬로 계산한 뒤 FeedForward layer는 chuncking 하여 각각 순서대로 계산
결과
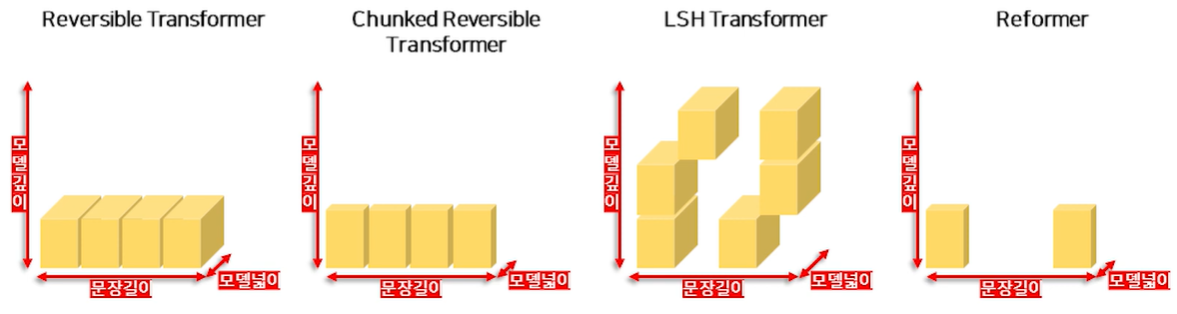
- Reversible Transformer : 중간 계산 과정을 저장할 필요가 없어 모델의 깊이가 줄어듦
- Chuncked Transformer : 분절(Chuncking)을 이용한 FeedForward 계산을 통해 모델의 넓이가 줄어듦
- LSH Attention : 필요한 부분만 Attention 하여 전체적으로 군데군데 빈 곳이 생겨 연산량이 줄어듦
- Reformer : 위의 모든 개념을 통합하여 연산량을 대폭 줄임
단점
- Reversible Network를 사용하여 학습 시간이 극단적으로 늘어남
Reference
https://arxiv.org/abs/2001.04451
Reformer: The Efficient Transformer
Large Transformer models routinely achieve state-of-the-art results on a number of tasks but training these models can be prohibitively costly, especially on long sequences. We introduce two techniques to improve the efficiency of Transformers. For one, we
arxiv.org
https://tech.scatterlab.co.kr/reformer-review/
꼼꼼하고 이해하기 쉬운 Reformer 리뷰
Review of Reformer: The Efficient Transformer
tech.scatterlab.co.kr
https://www.youtube.com/watch?v=6ognBL6DEYM&t=2008s
'자연어처리(NLP)' 카테고리의 다른 글
| [초등학생도 이해하는] Llama 3.1 초간단 정리 (33) | 2024.07.31 |
|---|---|
| ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS 논문 리뷰 (0) | 2023.05.19 |
| Big Bird: Transformers for Longer Sequences 논문 리뷰 (0) | 2023.05.13 |
| 4. 단어 수준 임베딩 (NPLM, Word2Vec, FastText, 잠재 의미 분석, Glove, Swivel) [초등학생도 이해하는 자연어처리] (0) | 2023.04.10 |
| 2. 자연어처리 임베딩 종류 (BOW, TF-IDF, n-gram, PMI) [초등학생도 이해하는 자연어처리] (0) | 2023.04.08 |