안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다.
오늘부터는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅하도록 하겠습니다. 제목처럼 진짜 핵심 내용을 쉽게 설명하는 것을 목표로 하고 있으니 자연어 처리(NLP)에 입문하고 싶은 분들은 많은 관심 부탁드립니다. 오늘 알아볼 내용은 '임베딩'입니다.
임베딩 (embedding)
- 임베딩 : 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과 혹은 그 일련의 과정
기본적으로 컴퓨터는 숫자를 이용하여 계산 하는 '계산기'입니다. 이러한 계산기가 사람의 언어인 자연어를 처리하게 하려면 자연어를 숫자로 바꿔 입력을 해주어햐 합니다. 이 과정을 '임베딩'이라고 합니다.
표1
가장 간단한 형태의 임베딩은 단어의 빈도를 이용한 것입니다. 위 표1을 보시면 각 작품별로 사용된 단어의 빈도수들이 나와있습니다. 예를들어 '운수 좋은 날'의 문서 임베딩은 [2, 1, 1]이고 '막걸리'라는 단어 임베딩은 [0, 1, 0, 0]이 됩니다. '막걸리'와 '선술집'의 단어 임베딩은 둘다 [0, 1, 0, 0]으로 비슷한 의미를 가진 단어라고 생각해 볼 수 있습니다.
임베딩의 역할
- 단어/문장 간 관련도 계산
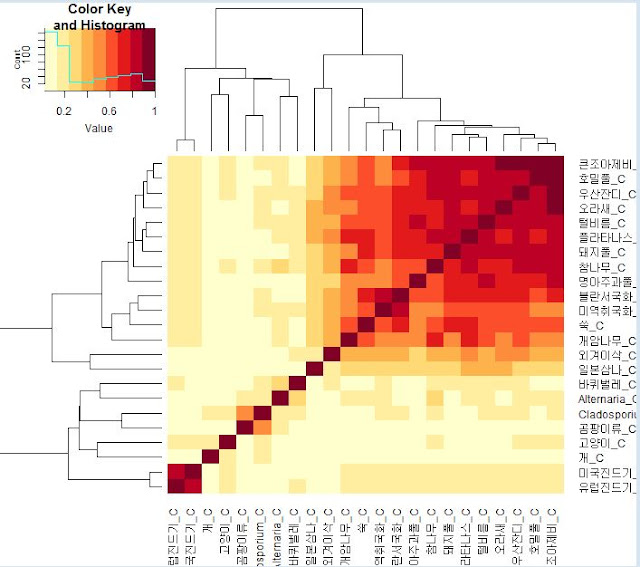
단어를 벡터로 임베딩 하면 단어간 유사도를 구할 수 있습니다. 위 그래프에서 진한 붉은색은 높은 유사도를, 연한색은 낮은 유사도를 의미합니다. 진드기류는 진드기류끼리, 식물은 식물류끼리 비슷한 것을 확인 할 수 있습니다.
- 의미적/문법적 정보 함축
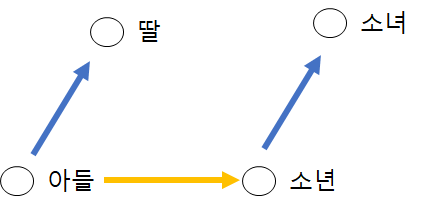
임베딩은 벡터로써 사직연산이 가능합니다. 아들과 딸의 관계는 소년과 소녀의 관계와 같습니다. 이러한 평가 방법을 '단어 유추 평가(word analogy test)'라고 합니다.
- 전이 학습
'전이학습'은 이미 학습된 모델을 이용해 다른 딥러닝 모델을 학습하는 것을 의미합니다. 단어 임베딩의 관점에서 보면 이미 학습된 단어 임베딩을 다른 언어모델에 사용하는것으로 볼 수 있습니다.
아래 그림들은 긍/부정 문서 분류 task에 '전이학습'결과를 보여준 것입니다. 'FastText'는 기존에 학습된 임베딩을 학습에 사용한 것이고, Random은 처음에 랜덤한 임베딩을 사용한 것입니다. 그래프에서 보시다 시피 전이학습을 한 모델의 성능이 더 좋습니다.
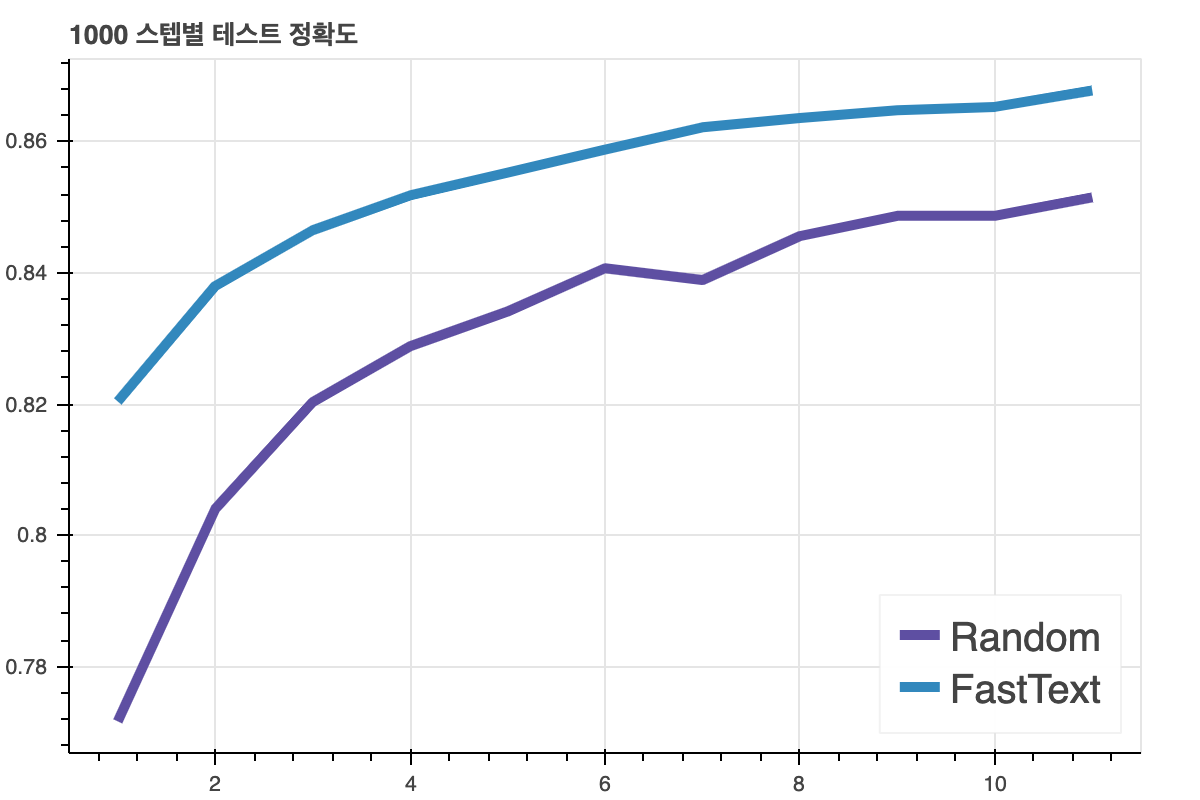
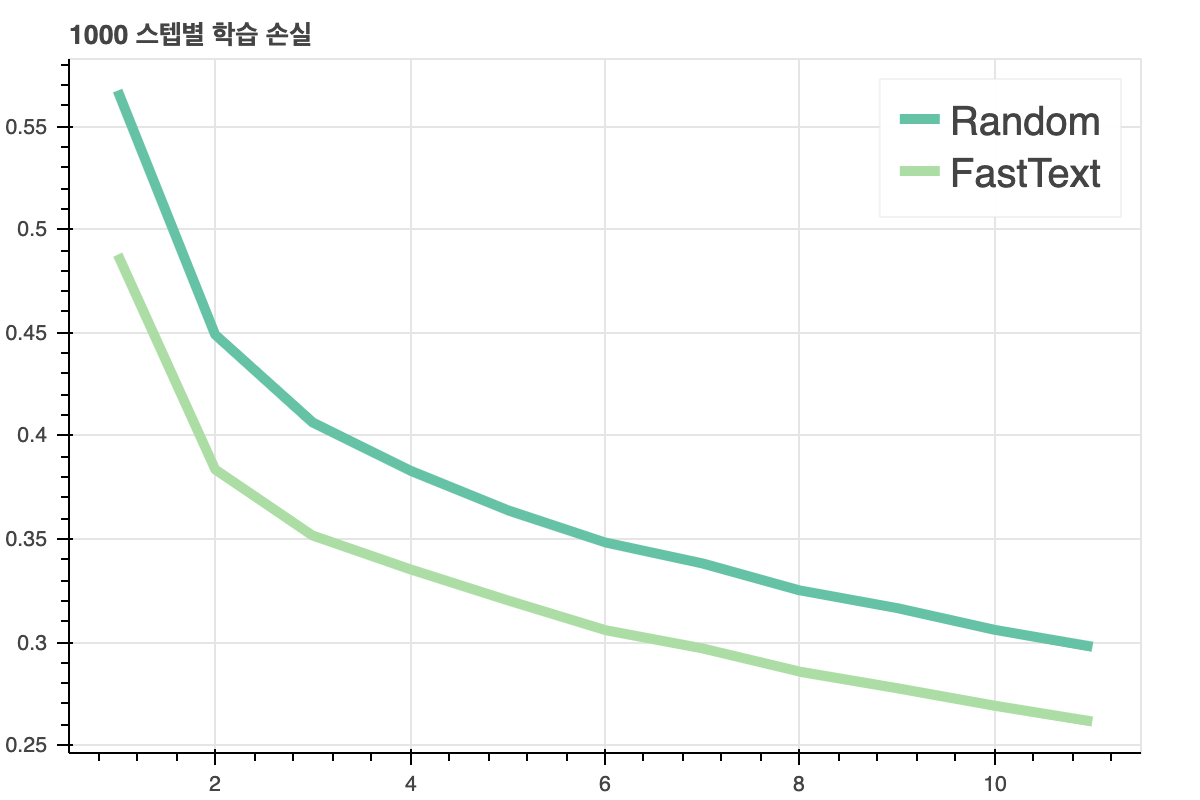
임베딩 기법의 종류
- 잠재 의미 분석(Latent Semantic Analysis, LSA) : 단어 사용 빈도 등 말뭉치의 통계량 정보가 들어 있는 커다란 행렬에 특이값 분해 등 수학적 기법을 적용해 행렬에 속한 벡터들의 차원을 축소하는 방법
임베딩을 하다보면 '원핫 인코딩'을 자주 사용하는데 이는 '0'을 많이 사용 합니다. 이러한 행렬을 '희소 행렬(sparse matrix)'라고 합니다. 희소 행렬은 의미없이 '0'을 많이 사용하여 연산량을 많이 잡아먹는데 이때 차원축소를 통해 연산량을 줄여줄 수 있습니다. 잠재 의미 분석 기법은 차원축소를 해주는 방법중에 하나입니다.
- 뉴럴 네트워크 기반 임베딩
최근에는 뉴럴 네트워크를 기반으로 한 임베딩 방법이 핫합니다. 이 모델들은 이전 단어들이 주어졌을 때 다음 단어가 뭐가 될지 예측하거나, 문장 내 일부분에 구멍을 뚫어 놓고(masking) 해당 단어가 무엇일지 맞추는 과정을 통해 학습됩니다.
- 단어 수준에서 문장 수준으로
- 단어 수준 임베딩 : NPLM, Word2Vec, Glove, FastText, Swivel
- 문장 수준 임베딩 : ELMo, BERT, GPT
기존 단어 수준 임베딩의 가장 큰 문제점은 '동음이의어(homonym)'를 분간하기 어렵다는 점 입니다. 그러나 문장 수준 임베딩에서는 문장의 문맥이 임베딩 안에 내포되어 전이 학습의 효과와 성능이 좋습니다.
- 룰 > 엔드투엔드 > 프리트레인/파인 튜닝
- 룰 : 피처를 사람이 직접 뽑는 방식. 즉 문법적인 부분을 사람이 룰로 만들어 사용
- 엔드투엔드 : 딥러닝을 이용하여 데이터 사이의 관계를 잘 근사해 언어모델을 학습
- 프리트레인/파인튜닝 : 업스트림 태스크(upstream task)를 통해 기본적인 언어를 파악할 수 있는 범용적인 모델을 학습시키고, 이후 전이 학습의 파인튜닝을 통해 다운스트림 태스크(downstearm task)를 진행하여 구체적인 목적성 있는 모델(품사 판별, 문장 성분 분석, 개체명 인식 등)들을 학습시킴
- 임베딩의 종류
- 행렬 분해 기반 방법 : 말뭉치 정보가 들어 있는 원래 행렬을 두 개 이상의 작은 행렬로 쪼개는 방식이 임베딩 (Glove, Swivel)
- 예측 기반 방법 : 어떤 단어 주변에 특정 단어가 나타날지 예측하고 무엇일지 맞추면서 학습하는 방식의 임베딩 (Word2Vec, FastText, BERT, ELMo, GPT)
- 토픽 기반 방법 : 주어진 문서에서 잠재된 주제를 추론 하는 방식으로 임베딩을 수행하는 방식의 임베딩 (LDA)
지금 까지 저희는 '임베딩(embedding)'에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이었습니다. 감사합니다.
reference : ''한국어 임베딩"



