안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Conducter'입니다.
오늘 알아볼 내용은 단변수 선형 회귀입니다.
선형 회귀(linear regression) : 종속 변수 y와 한 개 이상의 독립 변수(또는 설명 변수) X와의 선형 상관관계를 모델링하는 회귀분석 기법이다. 한 개의 설명 변수에 기반한 경우에는 단순 선형 회귀(simple linear regression), 둘 이상의 설명 변수에 기반한 경우에는 다중 선형 회귀라고 한다.
위에서 알아본 선형 회귀의 종류 중 단변수 선형 회귀는 말 그대로 변수가 하나인 선형 회귀입니다.
그러면 지금부터 예를 들어 설명하겠습니다.
먼저 아래와 같이 기본 라이브러리들을 불러줍니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 머신러닝 분석에 유용한 라이브러리
pd.read_csv 함수를 사용하여 csv 파일을 불러옵니다. 이 예제의 경우 집의 면적에 따른 집값을 비교하고 예측하는 알고리즘입니다. 따라서 변수는 'area'와 'price' 이렇게 2개입니다.
df = pd.read_csv("homeprices.csv")
# data frame
# csv파일을 읽어온다.
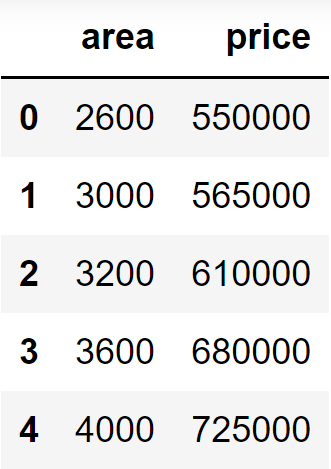
LinearRegression 함수의 '. fit'을 이용하여 area와 price를 학습시켜 줍니다. 이때 df[['area']]를 하는 이유는 x데이터가 여러 개 이므로 [[x1], [x2],...]식으로 만들어주기 위해서입니다.
reg = LinearRegression()
# regression
reg.fit(df[['area']], df.price)
# area, price데이터를 학습시켜준다.
'. predict'를 이용하여 원하는 area에서 price를 예측해 줍니다. 아래의 경우 area = 3300일 때 price = 628715로 예측됩니다.
reg.predict([[3300]])
# area=3300일때 price값을 예측
array([628715.75342466])
추가적으로 선형 예측된 모델의 기울기와 y절편을 구하고 싶으면 아래의 함수를 사용하면 됩니다.
reg.coef_
#기울기, y = m*x + b
reg.intercept_
#y절편
마지막으로 이를 그림을 그려주면 다음과 같습니다.
plt.scatter(df.area, df.price, color='red', marker='+')
plt.xlabel('area', size=20)
plt.ylabel('price', size=20)
plt.plot(df.area, reg.predict(df[['area']]), color='blue')

여기서 빨간 점은 실제 데이터, 파란선은 예측값들입니다. 보시다시피 잘 예측이 된 모습을 보이고 있습니다.
오늘은 단변수 선형 회귀에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 저는 '코딩 오페라'의 'Conductor'였습니다. 감사합니다.
<출처 및 참고 : 위키백과, code basics>
'머신러닝' 카테고리의 다른 글
| Support Vector Machine(SVM) (0) | 2022.01.20 |
|---|---|
| 로지스틱 회귀(Logistic Regression) (2) | 2022.01.12 |
| 학습 데이터와 훈련 데이터(Training Data and Testing Data) (0) | 2022.01.12 |
| 선형 회귀 모델의 수학적 해석(Gradient Descent and Cost Function) (0) | 2022.01.11 |
| 다변수 선형 회귀(Linear Regression Multiple Variables) (0) | 2022.01.10 |



