안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진짜 핵심 내용을 쉽게 설명하는 것을 목표로 하고 있으니 자연어 처리(NLP)에 입문하고 싶은 분들은 많은 관심 부탁드립니다. 이번 시간에 알아볼 내용은 'Self-Attention with Relative Position Representations' 논문입니다.
Abstract
- Transformer가 현재 기계 번역 분야에서 SOTA(state of the art)를 달성했지만 기존의 RNN, CNN과 달리 문서들의 상대적(relative) 또는 절대적(absolute) 위치 정보(positional information)가 명시되어있지 않음
- 이 논문에서는 이러한 문제점을 해결하기 위해 relative position 또는 단어 시퀀스(sequence) 사이의 거리를 이용하여 대안을 제시
Introduction
- RNN: 시계열적인 모델로, 시간 t를 통해 relative, absolute position 활용
- CNN: 본질적으로 각 컨볼루션(convolution)의 커널(kernel)로 인해 relative position 활용
- Transformer의 경우에는 위 두가지 RNN과 CNN 성질이 없어 따로 positional encoding을 해줘야 함
Background
- Transformer
아래 글 참조
https://codingopera.tistory.com/43
4-1. Transformer(Self Attention) [초등학생도 이해하는 자연어처리]
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진
codingopera.tistory.com
- Self-Attention
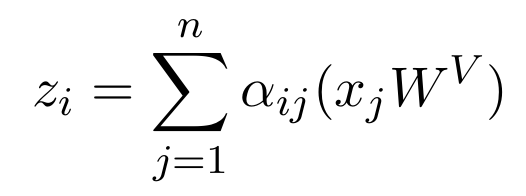

transformer의 attention 부분의 일반적인 모델은 위와 같이 구성
- x_j : input data
- z_i : output data
- W^(V) : 뉴럴네트워크(NN)의 weight
- a_ij : softmax 함수
한마디로 "input data가 NN을 통과하여 마지막으로 softmax 함수를 거치면 output이 됨"

Query와 Key를 이용하여 Attention Score 구하는법
- x_i : Query의 input
- x_j : Key의 input
- W^(Q) : Query의 NN
- W^(K) : Key의 NN
- d_z : input data의 임베딩 크기
- e_ij : attention score
Proposed Architecture
- Relation-aware Self-Attention
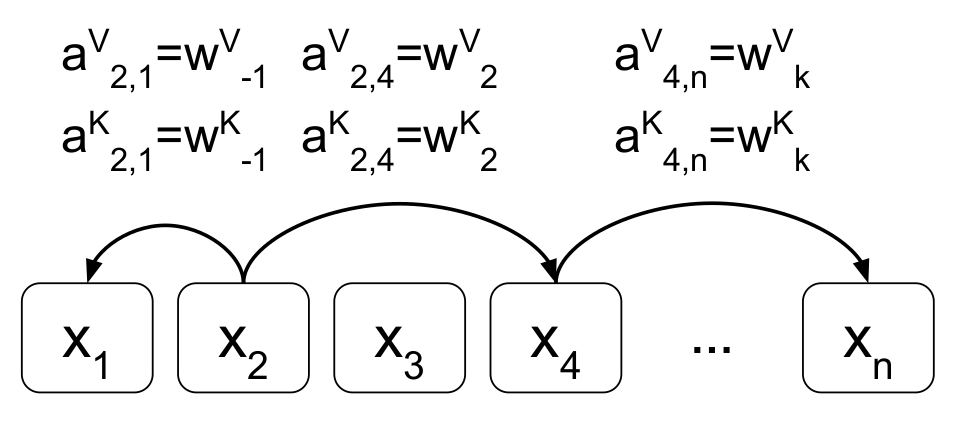
- relative position "a_ij^(V)"는 주체와 비교대상이 되는 단어의 상태적인 위치 차이를 나타내는 벡터
- 위의 그림과 같이 예를들어 x2에서 바라본 x1은 한칸앞에 있으므로 a_ij^(V) = W_(-1)^(V)가 되고, x2에서 바라본 x4는 두칸 뒤에 있으므로 a_ij^(V) = W_(2)^(V)가 됨


- 위의 input and output, attention score식들에 relative position "a_ij^(K or V)"를 더해주면 위와 같은 식이됨
- 여기서 ij의 의미는 i번째 단어와 j번째 단어 사이의 관계를 의미
- Relative Position Representations
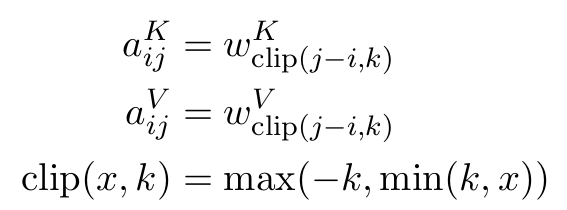
- 저자는 일정길이(절댓값 k) 이상 단어들이 떨어졌을 경우 이 때 거리차이(i - j)가 무의미 하다는 것을 발견
- 때문에 길이를 "절댓값 k"로 자름(clipping)
- Efficient Implementation
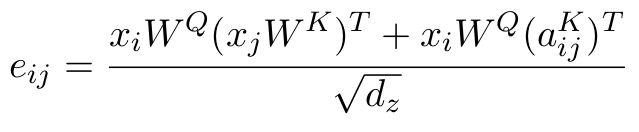
- 모든 시퀀스 및 헤드에서 각 position들은 다른 position들과 동일한 표현을 공유해야함
- relative position을 고려할 때, 각 위치 쌍마다 표현이 달라짐, 이는 모든 위치 쌍에 대한 e_ij를 하나의 행렬 곱셈으로 계산할 수 없게 만듦
- relative position 표현을 전파하고 싶지 않음
- 위의 문제들을 위의 "new attention score"식을 전개하여 바로 위의 식으로 만들면 해결됨 (왜 해결되는지는 아직 모르겠음!!)
Experiments

- 영어-독일어, 영어-프랑스어에서 Relative Position Representation을 사용했을때 Absolute Position Representation을 사용했을 때보다 BLEU score가 더 좋음

- 위 "Relative Position Representations"에서 cliping을 "k"만큼 하는데, k > 2일때는 별다른 의미가 없음

- a_ij^(V)와 a_ij^(K)의 유무에 따른 성능 비교
지금 까지 저희는 'Self-Attention with Relative Position Representations'에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이었습니다. 감사합니다.