반응형
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진짜 핵심 내용을 쉽게 설명하는 것을 목표로 하고 있으니 자연어 처리(NLP)에 입문하고 싶은 분들은 많은 관심 부탁드립니다. 이번 시간에 알아볼 내용은 'GPT: Improving Language Understanding by Generative Pre-Training'논문입니다.
Abstract
- Supervised Learning(지도 학습)은 데이터를 labeling 하는데 많은 시간과 돈이 들어가고, 심지어 데이터 양도 적음
- Unsupervised Learning(비지도 학습)은 반면 데이터 양도 풍부하고, 데이터 가공에 대한 추가적인 비용이 필요없음
- 이 논문에서는 pre-training(사전 학습)을 통해 다양한 task에 transfer learning을 할 수 있는 범용적 모델을 제안함
- 이후 fine-tuning(사후 학습)을 통해 다양한 task에 적용되어 학습
- 이러한 pre-training + fine-tuning 방식을 "Semi-supervised Learning"이라 함
Framework

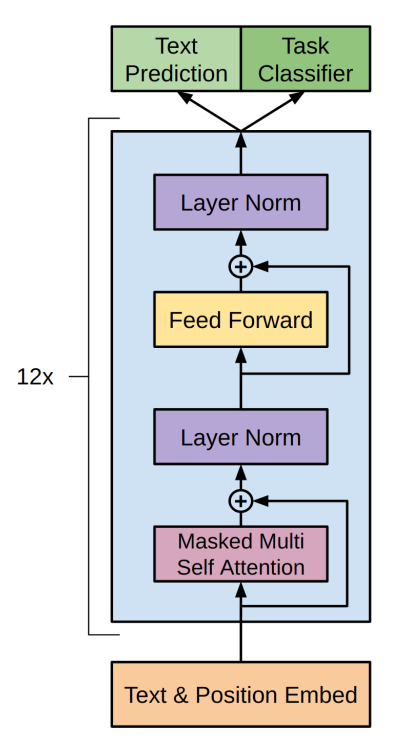
- GPT는 transformer의 decoder으로만 구성
- 따라서 원래 transformer의 encoder에서 넘어온 정보를 받아들이는 decoder의 multi-head attention 블록이 필요 없음
1. Unsupervised pre-training

- u = {u1, u2, ... , un}: unsupervised corpus의 token들
- k: context window의 크기
- theta: neural network의 parameter
- P: 조건부 확률
- 즉 L1(U)는 unsupervised corpus로부터의 object function(목적 함수)로 앞의 k개의 단어들을 참조해 다음 단어 ui를 조건부 확률적으로 예측, 이 L1(U) object function을 최대화하는 방향으로 모델이 학습

- We: token embedding matrix
- Wp: position embedding matrix
- U: context vector의 token들
- h0는 첫 번째 hidden state로 token embedding과 position embedding의 가중합으로 구성됨
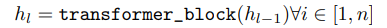
- GPT의 경우 transformer의 decoder를 계속 쌓아 올린 구조
- 따라서 l번째 hidden state는 이전 (l-1) 번째 hidden state가 input으로 들어간 trasformer encoder의 output임

- hidden state와 token embedding matrix를 이용하여 다음 단어를 예측
2. Supervised fine-tuning
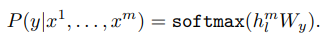
- hl^(m): 마지막 transformer 블록의 output
- Wy: linear layer의 parameter들
- 즉 supervised fine-tuning 확률은 쌓여있는 transformer 블록들의 마지막 output에 linear layer을 추가하고 softmax활성함수를 거친 값
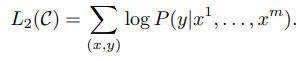
- C: labeling 된 data set
- L2(C)는 labeling된 data set으로부터의 object function(목적 함수)로 정답 y에 대한 확률값을 최대화하는 방향으로 학습

- L1(C): labeled data set에 대한 Unsupervised pre-training object function(목적 함수)
- L2(C): labeled data set에 대한 Supervised pre-training object function(목적 함수)
- lambda: weight
- 학습 시 Unsupervised pre-training object function과 Supervised pre-training object function을 같이 사용하면 성능이 더욱 향상됨 지피티지피티
- 일적인 성능 향상
- 수렴속도 증가
Results

- 전반적으로 제안된 GPT Language Model이 높은 성능을 보임
지금 까지 저희는 'GPT'에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이었습니다. 감사합니다.
reference
반응형



