안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진짜 핵심 내용을 쉽게 설명하는 것을 목표로 하고 있으니 자연어 처리(NLP)에 입문하고 싶은 분들은 많은 관심 부탁드립니다. 이번 시간에 알아볼 내용은 'PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization'논문입니다.
Abstract
- 최근 self-supervised objectives(pre-training and fine-tuning)을 이용한 대형 언어 모델들이 좋은 성능을 보임
- 그러나 이러한 모델들 중 abstractive text summarization(추상적 문서 요약. 모르면 아래 글 참조)에 맞게 설계된 모델이 없음. 또한 평가 방법도 부족함
- Extractive text summarization: 본문에서 문장을 그대로 추출 요약
- Abstractive text summarization: 본문의 내용을 이해하여 문서를 재창조해 요약
https://codingopera.tistory.com/48
BERTSUM: Text Summarization with Pretrained Encoders 논문 리뷰
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진
codingopera.tistory.com
- 따라서 이 논문에서는 새로운 self-supervised objective인 "pretraining large Transformer-based encoder-decoder"모델을 제안함
Gap Sentences Generation(GSG)
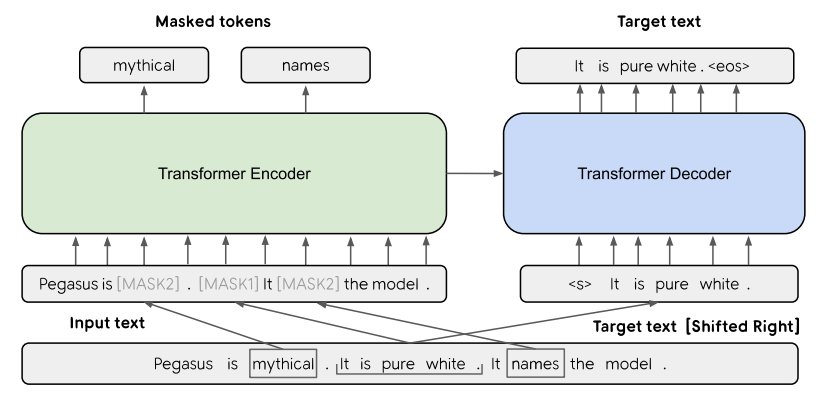
- 모델이 좋은 성능을 얻기 위해서는 적용하고자 하는 downstream task 목적에 맞는 pre-taining 모델을 사용하고, 이를 fine-tuning 해야 함
- Text summarization(문서 요약)을 수행하기 위해서는 원본 문서와 summarization(요약) 문서의 쌍이 필요하는데, 단순히 extractive 방식으로 summarization 문서를 추출하면 모델이 요약을 할 때 원본 문서에서 복사하는 방식으로 학습이 됨
- 이러한 문제를 해결하기위해 masking words와 contiguous spans(인접한 범위) 방식을 이용해 Gap Sentences Generation(GSG) 수행
- 위 그림의 [MASK1]: Gap Sentences Generation(GSG)
- [MASK2]: Masked Language Model(MLM)
- Gap Sentences Generation(GSG)
- 원본 문서로 부터 전체 문장을 통으로 선택하고 masking 함. 이 때 선택된 문장을 gab-sentence라고 함
- pseudo-summary에 gab-sentences를 이어 추가함
- 선택된 각 gab-sentence의 위치를 "mask token [MASK1]"으로 교체하여 모델에 줌
- Gap Sentences Ratio(GSR)
- 위에서 gab-sentence를 선택하는 비율을 의미
- GSR = gap-sentences 개수 / 전체 문장 개수
- Gap Sentences 선택 방법
- Random: m개의 문장들을 랜덤 하게 선택
- Lead: m개 문장들을 문서의 앞 부분 부터 순서대로 선택
- Principal: 선택한 gap-sentence와 나머지 다른 문장들 사이의 ROUGE1-F1 score를 통해 상위 점수 순으로 선택. 선택 기준은 다음과 같음
- Independently(Ind), Sequentially(Seq)
- n-grams as a set(Uniq), Original implementation(Orig)


Masked Language Model(MLM)
- BERT에서 사용된 masking 방법
- 전체 input token의 15%를 선택하여, 이 것의 80%는 mask token으로 변환하고, 나머지 10%는 random token, 그 나머지 10%는 원본 token으로 사용하는 방식 (좀 더 자세히 알고 싶으면 아래 글 참조)
- PEGSUS 모델에서 GSG와 MLM 방식이 둘 다 사용되었으나, MLM 방식이 down-stream task의 성능 향상에 영향을 끼치지 못해 최종 모델에서 제외함
https://codingopera.tistory.com/47?category=1094804
5. BERT(Bidirectional Encoder Representations from Transformers)
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진
codingopera.tistory.com
Effect Of Pre-training Objectives

- 각 GSG 방식(random, lead, ind-orig 등)과 pre-training 데이터셋(XSum, CNN/DailyMail, WikiHow, Reddit TIFU)에 따른 테스트 결과
- 각 GSR에 따른 결과
Effect Of Vocabulary
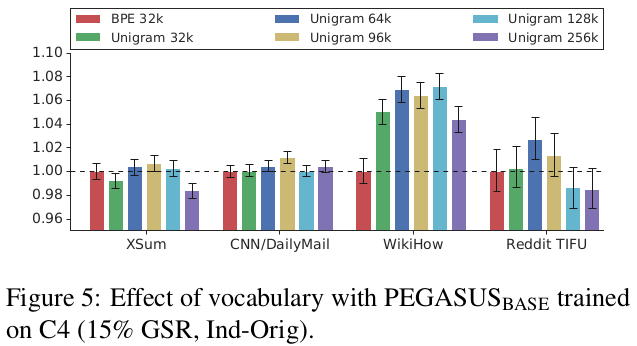
- tokenization 방법인 Byte-pair-encoding(BPE)와 SentencePiece Unigram(Unigram) algorithm 에 따른 성능 비교
- Unigram 방식이 앞도적으로 우세
Conclusion

- Abstractive summarization이라는 특정 task를 위해 GSG(Gap-Sentence Generation)라는 새로운 pre-training 기법을 적용
- 적은 학습 리소스(1000 examples)만으로 대부분의 결과에서 SOTA 달성
지금 까지 저희는 'PEGASUS'에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이었습니다. 감사합니다.
Referece
https://paperswithcode.com/paper/pegasus-pre-training-with-extracted-gap
Papers with Code - PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
🏆 SOTA for Abstractive Text Summarization on AESLC (ROUGE-1 metric)
paperswithcode.com
[Paper Review] PEGASUS:Pre-training with Extracted Gap-sentences for Abstractive Summarization
Intro최근 NLP의 downstream tasks 중 하나인 Summarization분야에 "PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization"이라는 새로운 논문(멋진 이
velog.io



