안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진짜 핵심 내용을 쉽게 설명하는 것을 목표로 하고 있으니 자연어 처리(NLP)에 입문하고 싶은 분들은 많은 관심 부탁드립니다. 이번 시간에 알아볼 내용은 'BERTSUM: Text Summarization with Pretrained Encoders'논문 입니다.
등장 배경
기존의 pretrained language model의 문장과 문장수준의 이해를 넘어 광범위한 이해를 통해 text summarization을 구현하고자 함.
Text Summarization의 종류
- Extractive Summarization:
문서에서 가장 중요한 문장을 그대로 이용하여 text summarization을 진행.
- Abstractive Summarization: "Extractive Summarization"과 달리 문서에서 추출하지 않고 문서를 전반적으로 이해하여 문장을 새로 생성해 text summarization을 진행.
BERTSUM의 특징
- Summarization Encoder
- 기존 BERT의 문제점
- masked-language model을 사용하기 때문에 output이 sentence(문장)가 아니라 token(단어)에 기초하였음. -----> 그러나 text summarization에서는 sentence(문장)-level이 중요함.
- 오직 두개의 sentence(문장)만 모델이 사용. -----> text summarization에서는 여러개의 sentence(문장) inputs 필요.
- positional embedding의 길이가 최대 512로 제한.

- 해결방안
- 여러 문장의 특징을 추출하기 위해 모든 문장의 시작에 "[CLS](classification)" token, 끝에는 "[SEP](seperate)" token을 삽입. ([CLS] token은 이전 문장의 features(특징)을 가지고 있음)
- 여러 문장들을 구별할 수 있도록 segment embedding을 EA, EB, EA, EB ..... 이렇게 문장별로 교차적용
- 인코더에서 랜덤하게 초기화 되고 다른 parameters들과 fine-tune하는 positional embedding을 추가
- 하위 transformer layer는 인접한 문장을 표현하고, 상위 transformer layer는 self-attention을 이용해 여러 문장의 결합을 표현
- Extractive Summarization
- 각 sentence(문장)가 summarization text(요약문)에 포함시킬지 말지 {0, 1}로 이진분류함
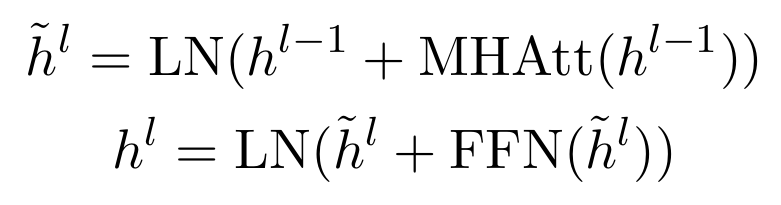

- 과정의 위 식과 같이 진행됨. h는 transformer에서 나온 output으로, L(l)은 transformer가 쌓인 층수를 의미함. 이 논문에서는 L=2일때 성능이 가장 좋았다고함. 나머지 변수들음 다음과 같음.
- LN: layer normalization operation
- MHAtt: Multi Head Attention
- FFN: Feed Forward Network
- hi^(L): L개층의 hidden state
- Abstractive Summarization
- BERT의 encoder는 사전학습 되어있고, decoder는 랜덤으로 초기화 되어 있음
- 때문에 이러한 상황에서 fine-tuning을 하면 encoder는 overfit되고, decoder는 underfit되는 문제가 발생함
- 이를 해결하기위해 fine-tuning shedule을 도입하여, encoder와 decoder에 각각 다른 warmup-step과 learning rate 적용
지금 까지 저희는 'BERTSUM'에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이었습니다. 감사합니다.
참조
https://paperswithcode.com/paper/fine-tune-bert-for-extractive-summarization
Papers with Code - Fine-tune BERT for Extractive Summarization
#2 best model for Extractive Document Summarization on CNN / Daily Mail (ROUGE-1 metric)
paperswithcode.com
https://kubig-2021-2.tistory.com/53
4. BertSum: Text Summarization with Pretrained Encoders 논문 리뷰
Abstract 본 논문에서는 BERT를 extractive, abstractive model 모두에게 사용할 framework를 제안한다. Extractive encoder의 맨 위에 inter-sentence Transformer layer를 쌓아서 생성 Abstractive 새로운 Fine-tuning schedule Two-staged
kubig-2021-2.tistory.com



