안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진짜 핵심 내용을 쉽게 설명하는 것을 목표로 하고 있으니 자연어 처리(NLP)에 입문하고 싶은 분들은 많은 관심 부탁드립니다. 지금부터 알아볼 내용은 'Transformer'입니다. Transformer 개념은 너무 방대하기 때문에 이번 시간에는 "Positional Encoding"을 집중적으로 다루겠습니다. 이후 내용들은 다음 글에서 다루도록 하겠습니다.
본론에 들어가기에 앞이 이분은 "Attention"과 "Self Attention"에 대한 사전 지식이 있어야 이해하기가 쉽습니다. 혹시 이 부분을 보시지 않으신 분들은 아래 링크의 글을 먼저 숙지하고 오시기 바랍니다. 그럼 지난 시간에 이어서 이번 시간에는 Positional Encoding에 대해 알아보도록 하겠습니다.
https://codingopera.tistory.com/43
4-1. Transformer(Self Attention) [초등학생도 이해하는 자연어처리]
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진
codingopera.tistory.com
Positional Encoding

우리는 흔히 시간이 흐른다라고 생각합니다. 그러나 상대성이론에 따른 면 사실 시간은 흐르지 않습니다. 위 그림은 빅뱅으로부터의 우주모형을 나타낸 것입니다. 여기서 x축은 시간축을 의미하는데, 이미 우주는 4차원의 도형으로 정해져 있고 우리가 사는 3차원의 하위 차원이 x축의 방향으로 빛으속도로 움직이고 있다는 것입니다. 이해를 돕기 위해 예시를 들겠습니다. 동영상은 2차원의 사진들이 시간 차원을 축으로 쌓여있는 3차원의 도형으로 생각할 수 있습니다. 때문에 이 영상의 정보는 3차원의 도형 형태로 모두 정해져 있으나, 영상 재생 시 우리는 2차원의 하위 차원을 시간축으로 변화시키기 때문에 시간에 따라 사물이 움직이는 것으로 생각이 되느것입니다. 이 원리는 우리가 사는 3차원 공간상에 적용하면, 우주는 시간축을 포함한 4차원 시공간 도형이고, 우리는 3차원의 흐름을 "시간이 흐른다."라고 느끼는 것입니다. 좀 더 자세한 설명을 원하시면 아래 영상을 참고하시기 바랍니다.

https://www.youtube.com/watch?v=h5EJZNIqN0k&ab_channel=1%EB%B6%84%EA%B3%BC%ED%95%99
앞선 글에서 설명했듯이, 연산처리를 할 때 병렬로 한번에 처리를 하면 효율적인 연산을 진행할 수 있습니다. 때문에 Transformer 메커니즘에서는 문장을 한 번에 연산처리를 합니다. 그런데 문제가 발생했습니다. 기존 RNN계열의 모델은 시간 순서대로 학습을 진행하기 때문에 상관이 없었지만, Transformer모델에서 문장을 한 번에 처리하자 단어 간의 순서가 반영이 되지 않은 것입니다. 언어는 시계열 데이터이기 때문에 문장에서 순서는 해석에 지대한 영향을 끼칩니다. 예를 들어 "나는 고기를 먹었다."라는 문장이 있을 때, 만약 주어"나"와 목적어"고기"가 바뀌면 "고기는 나를 먹었다."가 되어 문장의 의미가 완전히 달라집니다.
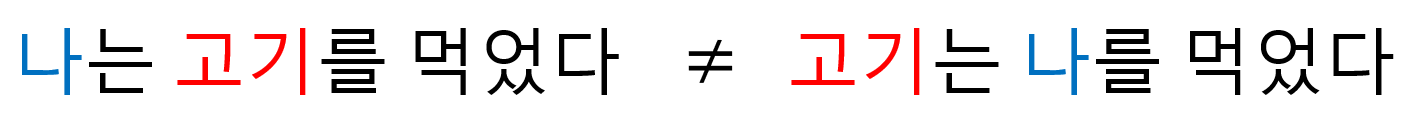
그러면 어떻게 이러한 시간 순서 문제를 해결할 수 있을까요? 답은 의외로 간단합니다. 각 단어 임베딩에 순서가 들어간 정보를 더해주면됩니다. 예를 들어 위에서 "나는 고기를 먹었다."라는 문장의 경우 각 단어들의 embedding 벡터에 각 단어들의 position embedding을 아래와 같이 더해주면 됩니다.

이때 positional embedding의 조건은 다음과 같습니다.
- 모델의 효율적인 학습을 위해 스케일이 어느정도 범위 안에 있어야 된다. 만약 positional embedding의 스케일 범위가 너무 크면 이 자체 값의 영향력이 너무 커져 다른 값(단어 embedding 등)이 무시되어 학습이 되지 않는다.
- input data의 크기에 상관없이 output을 도출해야된다. 만약 input data의 크기가 10일 때에 대해서만 output을 도출할 수 있다면, 다른 사이즈의 input data에 대해서는 output을 도출할 수 없다.
이러한 조건을 모두 만족하는 함수가 바로 아래 그래프와 같은"삼각함수" 입니다. (파란색: cos, 빨간색: sin, 초록색: linear) 우선 삼각함수의 경우 output값의 범위가 -1 ~ 1 사이로 안정적입니다. 또한 주기 함수이므로 x값에 상관없이 output값을 도출해 낼 수 있습니다. 만약 linear 함수를 사용한다면 x값이 커질수록(단어가 문장의 뒤에 있을수록) positional embedding값이 커져 학습이 잘 되지 않을 수 있습니다.

그러나 이러한 주기함수의 치명적인 단점은 y값이 주기적으로 반복돼, 정보가 겹친다는 것입니다. 이를 해결하기 위해 cos와 sin함수를 모두 사용하고, 각 embedding의 차원별로 sin, cos함수를 번갈아가며 사용합니다. 아래 수식을 보시면, embedding차원이 짝수이면 sin함수를, 홀수면 cos함수를 사용하는 것을 확인할 수 있습니다. 이렇게 구한 positional embedding 벡터를 위의 그림에서와 같이, 단어 embedding 벡터와 더해주면 "positional encoding"작업이 완성됩니다.

여러분들의 이해를 돕기위해 예시를 들어보도록 하겠습니다. 위에서 언급한 "나는 고기를 먹었다"라는 문장은 "나는", "고기를", "먹었다" 이렇게 3개의 단어들로 나뉩니다. 각 단어들의 차원을 d라고 하고 여기서는 d=4라고 정의하겠습니다. 여기서 차원의 순서를 i라고 했을 때, 각 단어별 i값은 1부터 4까지(d=4 이므로)가 됩니다. 각 단어의 position은 0부터 시작하며, 이 문장의 경우 "나는"은 "0", "고기를"은 "1", "먹었다"는 "2"로 정의됩니다.

이제 이 값들을 위해서 정의한 positional encoding 공식에 대입하면 됩니다. "나는"의 경우 첫 번째 단어이므로 positon=0입니다. 이 단어 embedding의 첫 번째 차원은 i=1 이므로 positional encoding = cos(0/(10000^(2*0/4))) = 1이 됩니다. 마찬가지로 다음 두 번째 차원은 positional encoding = sin(0/(10000^(2*1/4))) = 0이 됩니다. 다른 차원들도 모두 구해주면 아래와 같은 값들이 나옵니다. 이를 최종적으로 단어 embedding과 더해주면 positional encoding 작업이 완성됩니다.

오늘 배운 내용에 대해 잘 이해가 안되신다거나, 부가적인 설명이 필요하시면, 아래 제 유튜브 영상을 참고하시면 됩니다.
정성스럽게 영상을 제작 했으니 꼭 한번 들러주세요 :)
https://www.youtube.com/watch?v=-z2oBUZfL2o
정리
- Positonal Encoding: 문장을 한번에 병렬 처리해버리는 Transformer에 단어 순서를 알려주기 위한 작업.
< Positional Encoding의 필요조건 >
1. 모델의 효율적인 학습을 위해 positional encoding 값은 특이값이 없는 일정한 범위 안에 존재해야 함
2. input data의 size에 상관없이 output 값을 도출해야 함
이를 만족하기 위해 "삼각함수(sin, cos)" 사용
추가적으로 제가 AI 학습 관련 오픈 카카오톡방을 만들었습니다. AI와 코딩 학습에 목말라 있으신분들이라면 누구나 들어와서 즐겁게 맘껏 정보공유와 AI 공부하시면 될 것 같습니다. 링크는 다음과 같이니 꼭 한번 참석 및 홍보 부탁드리겠습니다.
https://open.kakao.com/o/ggxse9sg
인공지능/AI/코딩 공부방(코딩오페라)
인공지능/AI/코딩 공부방
open.kakao.com
추가적으로 Transformer에 대해 좀더 자세히 알고싶으신 분들은 아래 제 유튜브 영상을 참고하시면 됩니다.
정성스럽게 영상을 제작 했으니 꼭 한번 들러주세요 :)
[Transformer의 Attention(Self-Attention, Multi-Head Attention)]
https://www.youtube.com/watch?v=SR4F6WMqZ0s
[Transformer의 Residual Connection과 Layer Normalization]
https://www.youtube.com/watch?v=eq4zlaqaDvI
지금 까지 저희는 'Transformer의 Positonal Encoding'에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이었습니다. 감사합니다.
'자연어처리(NLP)' 카테고리의 다른 글
| BERTSUM: Text Summarization with Pretrained Encoders 논문 리뷰 (0) | 2023.01.30 |
|---|---|
| 5. BERT(Bidirectional Encoder Representations from Transformers) (0) | 2023.01.16 |
| 4-2. Transformer(Multi-head Attention) [초등학생도 이해하는 자연어처리] (2) | 2022.12.14 |
| 4-1. Transformer(Self Attention) [초등학생도 이해하는 자연어처리] (12) | 2022.12.13 |
| 3. Attention [초등학생도 이해하는 자연어처리] (12) | 2022.11.09 |



