안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다.
오늘 알아볼 내용은 'A3C'입니다.
저의 경우 2016년 알파고와 이세돌의 바둑 대결로 인해 인공지능에 관심이 많이 생기기 시작했고 이후 구글의 딥마인드 팀에서 발표한 DQN논문 특히 아타리사의 '브레이트 아웃' 게임을 하는 것을 보고 많은 감명을 받아 '강화 학습'이라는 학문에 많은 관심을 갖게 되었습니다. 그래서 오늘부터는 강화 학습에 대해 차분히 정리를 해보도록 하겠습니다.
저는 '파이썬과 케라스로 배우는 강화 학습'이라는 책을 읽으면서 독학을 하였습니다. 이 글은 이 책을 참고하여 제작합니다.(광고 아닙니다!!)
저번 시간에 우리는 DQN과 A2C알고리즘에 대해 알아보았습니다. 혹시 못 보신 분들은 아래 링크를 참고하시기 바랍니다.
https://codingopera.tistory.com/28?category=1063355
8. [강화학습] DQN(카트폴)
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 오늘 알아볼 내용은 'DQN'입니다. 저의 경우 2016년 알파고와 이세돌의 바둑 대결로 인해 인공지능에 관심이 많이 생기
codingopera.tistory.com
https://codingopera.tistory.com/30?category=1063355
10. [강화학습] A2C
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 오늘 알아볼 내용은 'A2C'입니다. 저의 경우 2016년 알파고와 이세돌의 바둑 대결로 인해 인공지능에 관심이 많이 생기
codingopera.tistory.com
에이전트는 환경과 상호작용하면서 샘플(s, a, r, s')을 생성하는데 이 샘플은 에이전트가 처한 상황에 따라 많이 변합니다. 또한 시간 순서대로 샘플을 학습하면 각 샘플끼리의 연관성 때문에 학습이 이상한 방향으로 될 수 있습니다. 이러한 문제를 해결하기 위해 DQN에서는 리플레이 메모리를 사용하여 샘플들을 저장하고 임의 배치만큼 추출해서 학습합니다. 그러나 리플레이 메모리를 사용하면 학습 속도가 느려지고 오프 폴리시 강화 학습만 사용해야 되는 단점이 있습니다.
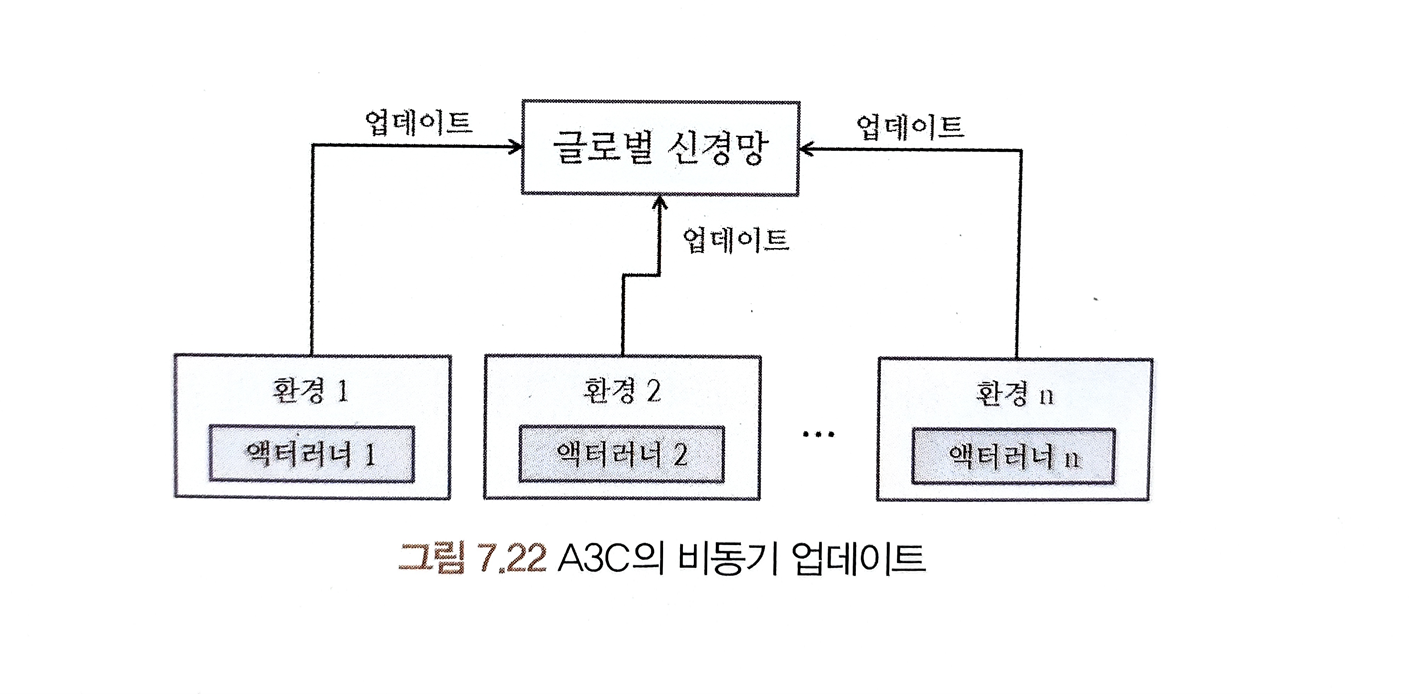
이러한 단점을 해결하기 위해 A3C알고리즘이 나왔습니다. DQN과 같이 메모리에 많은 샘플을 쌓아서 샘플 사이의 연관성을 깨는 것이 아니라 아예 에이전트를 여러 개 사용하는 것입니다. 샘플을 모으는 각 에이전트는 액터러너(Actor-Learner)라고도 합니다. 각 액터 러너는 각기 다른 환경에서 학습을 합니다. 따라서 액터 러너가 모으는 샘플은 서로 연관성이 현저히 떨어집니다. 액터 러너가 일정 타임 스텝 동안 모은 샘플을 통해 글로벌 신경망을 업데이트하고 자신을 글로벌 신경망으로 업데이트합니다. 여러 개의 액터 러너가 이 과정을 비동기적으로 진행하므로 A3C(Asynchronous Advantage Actor-Critic)
정리를 하자면
학습이 원활히 되려면 샘플간의 시간 연관성이 낮아야 한다.
1. DQN
- 리플레이 메모리를 사용해 위의 문제 해결
- 리플레이 메모리가 커질경우 학습 시간이 오래 걸림
- 리플레이 메모리를 사용할 결우 오프 폴리시에만 적용 가능
2. A3C
- 여러 개의 에이전트를 사용하여 샘플 간의 시간 연관성을 낮게 함
- 온 폴리시에도 적용 가능
'강화학습' 카테고리의 다른 글
| 11. [강화학습] 연속적인 A2C (0) | 2022.05.23 |
|---|---|
| 10. [강화학습] A2C (0) | 2022.04.26 |
| 9. [강화학습] REINFORCE (0) | 2022.04.26 |
| 8. [강화학습] DQN(카트폴) (0) | 2022.04.05 |
| 7. [강화학습] 딥살사(Deep SARSA) (0) | 2022.04.04 |