안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다.
오늘 알아볼 내용은 'A2C'입니다.
저의 경우 2016년 알파고와 이세돌의 바둑 대결로 인해 인공지능에 관심이 많이 생기기 시작했고 이후 구글의 딥마인드 팀에서 발표한 DQN논문 특히 아타리사의 '브레이트 아웃' 게임을 하는 것을 보고 많은 감명을 받아 '강화 학습'이라는 학문에 많은 관심을 갖게 되었습니다. 그래서 오늘부터는 강화 학습에 대해 차분히 정리를 해보도록 하겠습니다.
저는 '파이썬과 케라스로 배우는 강화 학습'이라는 책을 읽으면서 독학을 하였습니다. 이 글은 이 책을 참고하여 제작합니다.(광고 아닙니다!!)
저번 시간에 우리는 폴리시 그라디언트의 일종인 REINFORCE 알고리즘에 대해 알아보았습니다. 혹시 못 보신 분들은 아래 링크를 참고하시기 바랍니다. REINFORCE 알고리즘은 정책 기반 강화학습으로 굳이 가치 함수를 몰라도 된다는 장점이 있습니다. 그러나 에피소드가 끝날 때만 학습할 수 있다는 점과 에피소드가 길어지면 반환 값의 변화가 변화와 분산이 커진다는 단점이 있습니다. 이러한 단점을 해결하기 위해 고안된 알고리즘이 A2C(Advantage Actor Critic)입니다.
https://codingopera.tistory.com/29
9. [강화학습] REINFORCE
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 오늘 알아볼 내용은 'REINFORCE'입니다. 저의 경우 2016년 알파고와 이세돌의 바둑 대결로 인해 인공지능에 관심이 많이
codingopera.tistory.com
A2C는 REINFORCE 알고리즘의 단점을 해결하기 위해 다이나믹 프로그래밍의 정책 이터레이션 구조를 사용합니다. 정책 이터레이션은 정책 발전과 정책 평가로 이루어집니다. 폴리시 그라디언트에서 정책 발전의 경우 탐욕 정책 대신 정책 신경망의 업데이트를 이용합니다. 문제는 정책 평가인데, 아래 식에서 q(s, a)가 정책 평가의 역할을 합니다. 왜냐하면 큐 함수가 정책대로 행동했을 때 에이전트가 받으리라 기대하는 가치를 나타내기 때문입니다. 문제는 테이블 형태로 가치 함수와 큐 함수를 저장하는 것이 아니라서 q(s, a)를 알 수가 없다는 것입니다. 때문에 REINFORCE 알고리즘에서는 q(s,a)대신 반환 값 Gt를 사용한 것입니다. 다른 방법은 인공신경망으로 q(s, a)를 근사하는 것입니다. 이 인공신경망을 가치 신경망이라고 부르고 정책을 평가하는 것이기 때문에 크리틱(critic)이라고 이름을 붙였습니다. 이를 정리하면 아래와 같습니다.

<REINFORCE 알고리즘의 단점>
- 에피소드가 끝나야만 학습이 가능.
- 에피소드가 길어지면 반환값의 변화와 분산이 커진다.
<A2C>
- 정책 이터레이션 구조를 사용
- 정책 발전: 정책신경망의 업데이트를 이용(Actor)
- 정책 평가: 가치신경망의 업데이트를 이용(Critic)해 q(s, a) 근사
가치 신경망의 가중치를 w라고 한다면 A2C 업데이트식은 아래와 같게 됩니다.

오류 함수의 경우 크로스 엔트로피를 사용하게 되는데 오류함수의 정의는 다음과 같게 됩니다.
오류함수 = 정책 신경망 출력의 크로스 엔트로피 * 큐 함수(가치 신경망 출력)
그러나 이런 오류 함수를 사용하면 큐 함숫값에 의해 오류 함수가 많이 변화하게 됩니다. 그래서 이러한 변화 정도를 줄여주기 위해 사용하는 것이 '베이스라인(Baseline)'입니다. A2C에서는 가치 함수를 베이스라인 이로 사용합니다. 이 가치함수는 변수v에 의해 근사할 수 있습니다. 가치함수를 베이스라인으로 큐 함수에서 빼준 것을 어드벤티지(Advantage) 함수라고 하고 식으로 나타내면 아래와 같습니다.
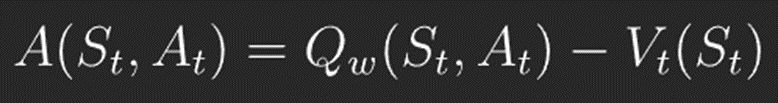
그러나 이러한 어드벤티지 함수를 사용하면 큐 함수와 베이스라인인 가치 함수를 따로 근사하기 때문에 비효율적입니다. 따라서 큐함수를 가치함수를 이용해 표현하면 아래와 같게 되고, 최종적으로 업데이트식은 다음과 같게 됩니다.

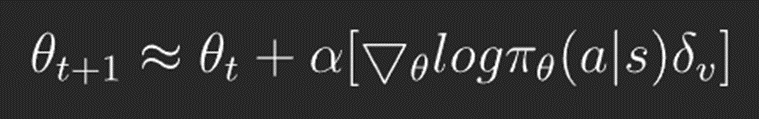
가치 신경망은 시간차 에러를 통해 학습을 진행합니다. 여기서 사용하는 오류 함수는 MSE를 사용합니다.


다시 한번 정리를 하자면
<A2C>
- 정책 이터레이션 구조를 사용
- 정책 발전: 정책 신경망의 업데이트를 이용(Actor)
오류 함수 = 크로스 엔트로피 * q함수(시간차 에러 MSE)
- 정책 평가: 가치 신경망의 업데이트를 이용(Critic)해 q(s, a) 근사
오류 함수 = 시간차 에러 MSE
지금 까지 저희는 'A2C'에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이었습니다. 감사합니다.
'강화학습' 카테고리의 다른 글
| 12. [강화학습] A3C (0) | 2022.05.23 |
|---|---|
| 11. [강화학습] 연속적인 A2C (0) | 2022.05.23 |
| 9. [강화학습] REINFORCE (0) | 2022.04.26 |
| 8. [강화학습] DQN(카트폴) (0) | 2022.04.05 |
| 7. [강화학습] 딥살사(Deep SARSA) (0) | 2022.04.04 |



