안녕하세요, Coding your life, '코딩 오페라'입니다. 오늘은 최근 많이 거론되는 ' RAG(Retrieval-Augmented Generation)'에 대해 소개해드리고자 합니다. 제목처럼 초등학생도 이해하기 쉽게 설명드렸으니, 인공지능(AI)에 입문하고 싶은 분들은 꼭 끝까지 읽어주세요 😀
[RAG란 무엇인가?]
1. RAG의 이슈화: 최근 왜 주목받고 있을까?
RAG는 최근 들어 AI의 신뢰성과 정확성을 개선하기 위한 핵심 기술로 부상하고 있습니다. 특히, LLM(대형 언어 모델)의 환각(hallucination) 문제를 완화할 수 있는 현실적 대안으로 각광받고 있죠. 여기서 환각이란, LLM이 그럴듯하지만 사실이 아닌 정보를 생성하는 현상을 의미합니다. 즉 한마디로 거짓된 정보를 그럴듯하게 말하는 문제를 의미합니다.
- 예를 들어, NVIDIA의 젠슨 황 CEO는 GTC 행사에서 “환각 문제는 RAG를 통해 ‘매우 해결 가능하다’”라고 말하며, RAG를 “단순한 챗봇이 아니라 연구 조수처럼 행동하는 방법”으로 설명했습니다.
- 또, Wired에서는 RAG가 AI가 ‘직접 만들어내는 것이 아니라’, 사용자 입력에 맞춰 외부 데이터베이스에서 정보를 “끌어와 답변을 뒷받침”한다고 강조했습니다.
결국, 지금 이 시점에서 RAG가 각광받는 이유는 바로 AI의 응답을 더 정확하고 신뢰성 있게 만들면서, 동시에 재학습( Retraining) 없이도 최신 정보 반영이 가능하다는 점이에요.
2. RAG의 정의
RAG(Retrieval-Augmented Generation)는 이름 그대로 '검색(Retrieval)'과 '생성(Generation)'을 합친 구조입니다. 이는 “검색해서 가져온 정보를 이용해 AI가 더 똑똑하고 믿을 수 있게 대답하도록 돕는 방법”이에요.
- 예를들어 숙제에 관련된 질문을 ChatGPT에게 했는데, ChatGPT가 “모르지만 적당한 답을 만들어냈다”면 이건 환각입니다.
- 그런데 RAG는 AI(LLM)가 “먼저 도서관(데이터베이스)에 가서 정확한 내용을 찾아오고, 그 정보를 바탕으로 대답하는” 방식이에요.
- 그러니까, AI가 “LLM 자기 자신의 생각에 대해 대답하는 게 아니라”, 최신 책이나 정보를 검색해서 가져와서 대답한다라고 이해하면 됩니다.
RAG는 본질적으로 검색 기반 모델과 생성 모델이라는 두 가지 AI 영역의 강점을 독창적으로 결합한 하이브리드 모델입니다. 이러한 융합을 통해 AI 시스템은 방대한 데이터베이스에서 관련 정보를 추출(검색)하고, 그 후 일관되고 맥락적으로 관련성 있는 응답(생성)을 생성할 수 있습니다. 이는 기존 모델에서 크게 도약하여, 인간과 유사한 텍스트를 이해하고 생성하는 데 있어 더욱 섬세하고 정교한 접근 방식을 제시합니다.
[RAG의 동작원리]
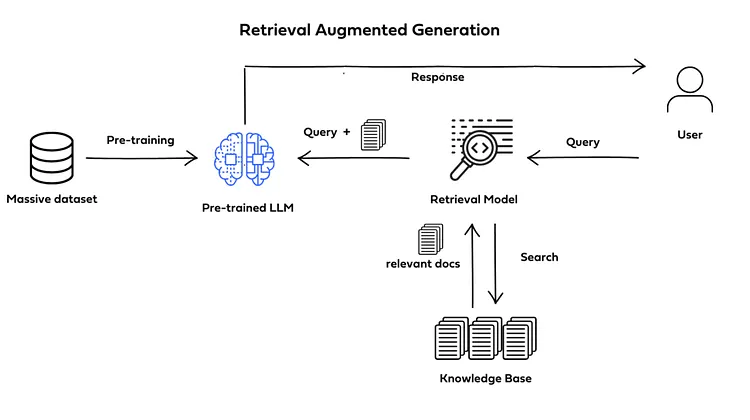
그렇다면 RAG는 어떤 구조로 이루어져 있으며, 각 모듈이 어떤 역할을 수행할까요? 이번 글에서는 RAG의 구성 요소와 동작 흐름을 모듈별로 알아보도록 하겠습니다.
1. RAG를 구성하는 핵심 모듈
RAG는 크게 네 가지 요소로 이루어져 있습니다. 각 모듈이 맡은 역할을 정확히 이해하면 RAG 시스템이 왜 효과적인지 쉽게 이해할 수 있습니다.
1-1. User (사용자)
사용자는 RAG 시스템에 질문을 입력하는 주체로, 자연어 형태의 Query를 생성하며, 전체 RAG 동작 흐름을 시작하는 출발점이 됩니다. 예를 들어 “삼성전자 주가는 앞으로 오를까?”와 같은 질문을 하는 주체라고 생각하시면 됩니다.
1-2. Pre-trained LLM (사전학습된 대규모 언어모델)
Pre-trained LLM은 사전에 학습된 대규모 언어모델으로, 주체자로부터 질문을 받고 이 질문의 의도를 Retrieval Model에 넘겨주는 역할을 진행합니다. 이때 Retrieval Model이 찾아준 문서들을 기반으로 최종 답변을 생성합니다. 최종 답변은 검색된 문서를 참고하여 분석, 요약, reasoning 등을 수행해 가장 자연스럽고 정확한 답변을 생성하고, 주요 모델로는 GPT, Llama, Mistral 등이 있습니다.
1-3. Retrieval Model (검색·임베딩 모델)
Retrieval Model은 사용자의 질문을 받은 Pre-trained LLM과 Knowledge Base에 저장된 문서를 중간에서 연동해주는 연동단 모델이라고 생각하시면 됩니다. 즉 이 모델은 주체자의 질문 의도가 담기 질문 벡터(embedding)를 이용하여 Knowledge Base에서 검색을 하여 질문과 가장 관련성 높은 문서를 찾아내는 역할을 수행합니다. 이렇게 검색을 진행하기 때문에 이름이 Retrieval Model로 정해졌습니다. 대표적인 모델로는 Sentence-BERT, DPR, E5 등이 있습니다.
1-4. Knowledge Base (지식 저장소 / 벡터 DB)
Knowledge Base는 RAG의 핵심 데이터 저장소입니다. 여기에는 텍스트 문서가 chunk 단위로 저장되며, 각 chunk는 미리 계산된 임베딩 벡터와 함께 보관됩니다. Retrieval Model이 검색 요청을 보내면, Knowledge Base는 가장 유사한 문서들을 반환해 LLM이 참고할 수 있도록 합니다. 즉, Knowledge Base는 우리가 검색하는 검색페이지(Google, Naver 등)나 백과사전과 같이 모든 지식이 집합되어있는 모듈이라고 생각하시면 됩니다. FAISS, Pinecone, ChromaDB 등이 대표적인 벡터 DB입니다.
2. RAG는 어떻게 동작할까? (순차적 흐름)
이제 각 모듈이 어떻게 상호작용하는지 전체적인 흐름을 순서대로 살펴보겠습니다.
2-1. 인덱싱 과정 (Indexing: 데이터 준비 단계)
외부의 방대한 데이터를 검색 가능한 상태로 변환하여 벡터 데이터베이스에 저장하는 사전 작업입니다.
- 문서 로더 (Document Loader): 다양한 형태의 외부 데이터를 파이썬이 처리할 수 있는 Document 객체 형식으로 읽어옵니다.
- 비정형 데이터 처리: PDF, Word, TXT, Markdown 등 파일 읽기.
- 웹/앱 연동: 웹 페이지 크롤링, Notion, Slack, Google Drive API 연동.
- 데이터 추출: 텍스트뿐만 아니라 메타데이터(페이지 번호, 작성일, 출처 등)를 함께 보존하여 나중에 검색 정확도를 높입니다.
- 텍스트 분할 (Text Splitting): 로드된 문서를 LLM이 처리하기 적절하고 검색 효율이 높은 **작은 조각(Chunk)**으로 자릅니다.
- 필요성: * 콘텍스트 제한: LLM은 한 번에 읽을 수 있는 양이 정해져 있습니다.
- 검색 정밀도: 문서 전체보다 질문과 밀접한 특정 부분만 찾아내는 것이 훨씬 정확합니다.
- 단순히 글자 수로 자르거나, 문단·재귀적 구조(Recursive)를 고려하여 의미가 끊기지 않게 자르는 기법을 사용합니다. (이때 조각 간에 약간의 겹침(Overlap)을 두어 문맥 유실을 방지합니다.)
- 임베딩 (Embedding): 분할된 텍스트 조각을 고차원적인 의미를 지닌 **숫자 리스트(Vector)**로 변환합니다.
- 의미적 수치화: "사과"와 "포도"는 숫자상으로 가깝게, "사과"와 "자동차"는 멀게 배치합니다.
- 모델 사용: OpenAI의 text-embedding-3-small이나 HuggingFace의 오픈소스 모델 등을 사용하여 변환합니다.
- 이 과정을 통해 컴퓨터는 단어의 철자가 달라도 의미가 유사한지를 수학적으로 계산할 수 있게 됩니다.
- 벡터 DB 저장 (Vector Store): 생성된 벡터와 원본 텍스트(청크)를 함께 저장하고, 고속으로 유사도 검색을 수행할 수 있는 데이터베이스에 보관합니다.
- 인덱싱: 수만 개의 벡터 중 질문과 가장 유사한 것을 0.1초 내에 찾을 수 있도록 최적화된 색인을 생성합니다.
- 관리: 데이터의 추가, 삭제, 업데이트를 지원합니다.
- 대표적 도구: Chroma, Pinecone, FAISS, Milvus 등.
2-2. 쿼리 과정 (Querying: 사용자 응답 단계)
사용자의 질문을 기반으로 저장된 데이터를 찾아 답변을 생성하는 실시간 실행 단계입니다.
- Retrieve (검색): 사용자의 질문을 인덱싱 때와 동일한 모델로 임베딩한 후, 벡터 DB에서 가장 유사한 관련 청크들을 찾아옵니다.
- Augment (증강): 검색된 정보와 사용자의 질문을 하나의 프롬프트 템플릿으로 합칩니다. ("다음 정보를 바탕으로 질문에 답해줘: [검색된 내용] + [사용자 질문]")
- Generate (생성): 보강된 프롬프트를 LLM에 전달하여, 모델이 외부 지식을 참고한 최종 답변을 생성하도록 합니다.
2-2-1. User → Retrieval Model : 질문 입력
사용자가 자연어로 질문을 입력하면 Retrieval Model은 이 질문을 임베딩 벡터로 변환합니다.
이 벡터는 이후 문서 검색과 유사도 비교의 기준이 됩니다.
2-2-2. Retrieval Model → Knowledge Base : 관련 문서 검색
변환된 질문 벡터는 Knowledge Base 내부의 수많은 문서 벡터들과 비교됩니다.
Nearest Neighbor Search를 통해 가장 유사한 문서 Top-k(예: 3~5개)를 찾으며, 이를 "context"라고 부릅니다.
2-2-3. Knowledge Base → Pre-trained LLM : 근거 문서 제공
Knowledge Base는 Retrieval Model이 요청한 문서 chunk들을 반환합니다.
이 문서들은 LLM이 답변을 생성할 때 참고할 정보이며, 환각(hallucination)을 줄이는 핵심 근거가 됩니다.
2-2-4. Pre-trained LLM → User : 최종 답변 생성
LLM은 사용자 질문과 검색된 문서를 하나의 입력으로 통합하여 분석합니다.
이를 통해 단순 생성이 아닌 **근거 기반 답변(grounded answer)**을 만들고, 최종적으로 사용자에게 응답을 제공합니다.
3. 전체 구조 한눈에 보기
문장을 간단히 정리하면 다음과 같은 순서입니다.
단순화된 흐름
User
→ 질문 입력
Retrieval Model
→ 질문 임베딩 및 유사 문서 검색
Knowledge Base
→ Top-k 문서(context) 반환
Pre-trained LLM
→ 검색된 문서를 바탕으로 답변 생성
User
→ 최종 응답 수신
핵심 포인트
- LLM 단독 사용 → 훈련 데이터에 한정, 환각 발생 가능
- RAG 사용 → 외부 DB 참조로 최신/정확한 답변 제공
즉, RAG는 “AI가 도서관을 다녀와서 답하는 과정”이라고 보면 됩니다.
[RAG의 필요성과 종류]
1. RAG가 왜 필요한가?
- 정확성과 신뢰성 향상
- 잘못된 정보 생성을 줄이고, 사용자 신뢰를 높임.
- 재학습 없이 최신 정보 활용
- 모델 재학습 없이도 최신 데이터 반영 가능.
- 투명성과 검증 가능성
- 참조한 자료의 출처를 함께 제공할 수 있음.
- 도메인 특화 활용
- 의학, 법률, 금융 등 최신성과 정확성이 중요한 분야에서 강력한 장점 발휘.
2. RAG의 종류 (Graph RAG 등)
- 일반 RAG (Vector-based RAG) : 벡터 DB에서 유사한 문서를 검색해 사용하는 가장 기본적인 방식.
- Graph RAG (Knowledge Graph 기반) : 문서 속 개체와 관계를 그래프 형태로 구조화해, 복잡한 연결 정보를 더 잘 이해.
- Dynamic RAG & Parametric RAG : 답변 생성 중 실시간으로 검색을 반복하거나, 파라미터 수준에서 검색 결과를 통합하는 새로운 방식.
- Multimodal RAG : 텍스트뿐 아니라 이미지, 그래프 등 다양한 데이터를 함께 검색해 활용.
3. 예시: 일상생활에서 어떻게 활용될까?
- 학교 숙제 도우미 : 최신 교과서/백과사전 검색 후 답변.
- 회사 내부 문서 검색 : 회의록·보고서에서 바로 답 찾아줌.
- 의료 상담 : 최신 의학 논문 기반 정보 제공.
- 법률 상담 : 실제 판례나 법령 전문을 검색 후 요약 제공.
[정리]
항목 핵심 내용 요약
| 이슈화 | 환각 문제 해결, 최신 정보 반영, 실질적 대안으로 부상 |
| 정의 (초보자) | “검색해서 가져온 정보로 AI가 더 정확하게 대답” |
| 동작 원리 | 질문 → 벡터 변환 → DB 검색 → LLM + 문서 → 답변 |
| 필요성 | 정확성↑, 비용↓, 신뢰성 및 투명성 확보, 도메인 적용 가능 |
| 종류 | Vector RAG, Graph RAG, Dynamic/Parametric RAG, Multimodal RAG 등 |
| 일상 예시 | 숙제, 회사 문서, 의료/법률 상담 등 다양한 분야에서 활용 가능 |
오늘 RAG에 대한 기본 개념에 대해 알아보았는데요, 이해가 잘 되셨나요? 다음 시간에는 RAG의 deep한 내용 및 실습을 해보는 시간을 갖겠습니다!
궁금한 사항이 있으시면, 언제든 댓글 남겨주세요!
그럼 다음에 만나요! 안녕 😀
Reference
https://medium.com/@krtarunsingh/introduction-to-retrieval-augmented-generation-rag-and-its-transformative-role-in-ai-c07e35da7f01
'자연어처리(NLP)' 카테고리의 다른 글
| [초등학생도 이해하는] Graph RAG (0) | 2025.09.16 |
|---|---|
| [초등학생도 이해하는] 챗지피티(ChatGPT) 가입부터 사용법까지 (1) | 2024.08.11 |
| [초등학생도 이해하는] 라마 3.1 설치 방법 초간단 정리(올라마, Ollama) (0) | 2024.08.07 |
| [초등학생도 이해하는] Llama 3.1 초간단 정리 (33) | 2024.07.31 |
| ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS 논문 리뷰 (0) | 2023.05.19 |