안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다.
현재 '초등학생도 이해하는 빅데이터분석기사 실기'라는 주제로 판다스(pandas)를 이용한 데이터 마이닝에 대해 포스팅을 진행하고 있습니다. 제목처럼 진짜 핵심 내용을 쉽게 설명하는 것을 목표로 하고 있으니 데이터 마이닝에 입문하고 싶은 분들은 많은 관심 부탁드립니다. 오늘 알아볼 내용은 '판다스 평균, 표준편차, 중앙값, 최대값, 최소값'입니다.
우리가 데이터를 분석하다 보면, 대부분의 경우 데이터의 평균, 표준편차, 중앙값 등 다양한 값들이 필요합니다. 그중에서 오늘은 가장 중요한 데이터의 평균, 표준편차, 중앙값, 최대값, 최소값에 대해 알아보도록 하겠습니다.
먼저 본론으로 들어가기 전 이 값들의 의미에 대해서 알아보겠습니다.
- 평균 (Mean) : 데이터 집합의 모든 값을 더한 후, 데이터의 개수로 나눈 값입니다. 예를 들어, 1, 2, 3, 4, 5의 평균은 (1+2+3+4+5) / 5 = 3입니다.
- 표준편차 (Standard Deviation) : 데이터의 분산 정도를 나타내는 측정 지표로, 평균으로부터 각 데이터 포인트가 얼마나 떨어져 있는지를 나타냅니다. 값이 작을수록 데이터가 평균 주변에 모여 있음을 의미하고, 값이 클수록 데이터가 흩어져 있음을 의미합니다.
- 중앙값 (Median) : 데이터를 크기 순서대로 정렬했을 때 중간에 위치한 값으로, 데이터 집합의 크기에 관계없이 이상치에 덜 민감합니다. 예를 들어, 1, 2, 3, 4, 5의 중앙값은 3입니다.
- 최대값 (Maximum) : 데이터 집합에서 가장 큰 값입니다. 예를 들어, 1, 2, 3, 4, 5의 최대값은 5입니다.
- 최소값 (Minimum) : 데이터 집합에서 가장 작은 값입니다. 예를 들어, 1, 2, 3, 4, 5의 최소값은 1입니다.
데이터 불러오기
자 그럼 이제 본론으로 넘어와 판다스를 이용해 각 값들을 구하는 법을 알아보도록 하겠습니다. 데이터 분석을 위해 사용하는 판다스 라이브러리는 엑셀처럼 이러한 값들을 자동으로 계산해 주는 함수를 가지고 있습니다.
데이터 분석 실습을 위해 우선 데이터를 불러오도록 하겠습니다.
import pandas as pd
df = pd.read_csv("basic1.csv")
df.head()
위 예시 'basic1.csv' 파일을 다운로드하고, 다음과 같이 pandas의 'read_csv'함수를 이용해 csv파일을 불러와줍니다. 참고로 이 부분에 대해 자세히 알고 싶으신 분들이 아래 포스트를 참고하시기 바랍니다.
https://codingopera.tistory.com/11
파이썬 csv 파일 불러오기
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Conducter'입니다. 오늘 알아볼 내용은 파이썬에 csv파일을 불러오는 것입니다. 그전에 우선 csv파일에 대해 알아보도록 합시다. csv(comma-separa
codingopera.tistory.com
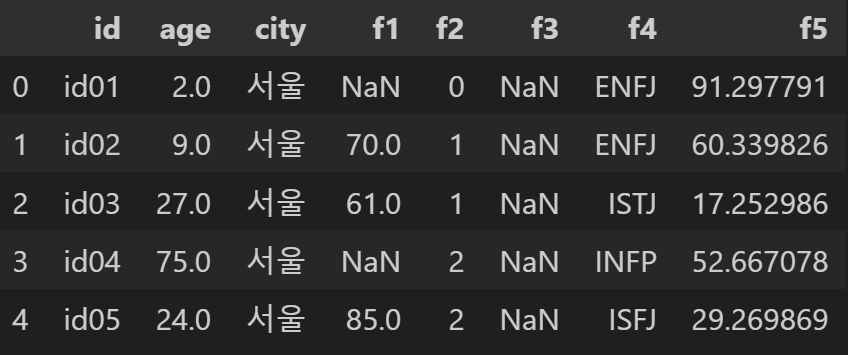
판다스 data frame을 print 하면 위 와 같이 나오게 됩니다. 이 정보를 활용해서 이게 평균, 표준편차, 중앙값, 최대값, 최소값을 구해봅시다.
평균 (Mean)
# 평균
mean_f2 = df['f2'].mean()
print(mean_f2)
판다스에서 평균은 'mean()' 함수를 통해 구할 수 있습니다. 위 코드와 같이 원하는 data frame의 행 또는 열에 mean() 함수를 붙여주면 됩니다. 정리하자면 형식이 "data frame [행 또는 열]. mean()" 이렇게 됩니다. 위 예시에서 f2열의 평균은 0.65입니다.
표준편차 (Standard Deviation)
# 표준편차
std_f2 = df['f2'].std()
print(std_f2)
판다스에서 표준편차는 'std()' 함수를 통해 구할 수 있습니다. 위 코드와 같이 원하는 data frame의 행 또는 열에 std() 함수를 붙여주면 됩니다. 정리하자면 형식이 "data frame [행 또는 열]. std()" 이렇게 됩니다. 위 예시에서 f2열의 표준편차는 0.7159792333764037 입니다.
중앙값 (Median)
# 중앙값
med_f2 = df['f2'].median()
print(med_f2)
판다스에서 중앙값은 'median()' 함수를 통해 구할 수 있습니다. 위 코드와 같이 원하는 data frame의 행 또는 열에 median()함수를 붙여주면 됩니다. 정리하자면 형식이 "data frame[행 또는 열].median()" 이렇게 됩니다. 위 예시에서 f2열의 중앙값은 1.0 입니다.
최대값 (Maximum)
# 최대값
max_f2 = df['f2'].max()
print(max_f2)
판다스에서 최대값은 'max()' 함수를 통해 구할 수 있습니다. 위 코드와 같이 원하는 data frame의 행 또는 열에 max()함수를 붙여주면 됩니다. 정리하자면 형식이 "data frame[행 또는 열].max()" 이렇게 됩니다. 위 예시에서 f2열의 최대값은 2 입니다.
최소값 (Minimum)
# 최소값
min_f2 = df['f2'].min()
print(min_f2)
판다스에서 최소값은 'min()' 함수를 통해 구할 수 있습니다. 위 코드와 같이 원하는 data frame의 행 또는 열에 min()함수를 붙여주면 됩니다. 정리하자면 형식이 "data frame[행 또는 열].min()" 이렇게 됩니다. 위 예시에서 f2열의 최소값은 0 입니다.
지금 까지 저희는 '판다스(pandas) 평균, 표준편차, 중앙값, 최대값, 최소값 '에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이었습니다. 감사합니다.



