안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진짜 핵심 내용을 쉽게 설명하는 것을 목표로 하고 있으니 자연어 처리(NLP)에 입문하고 싶은 분들은 많은 관심 부탁드립니다. 오늘 알아볼 내용은 요즘 핫한 뉴진스의 'Attention'입니다.
Attention 이란?


Attention이란 문맥에 따라 집중할 단어를 결정하는 방식을 의미합니다. 우리는 글을 읽을때 모든 단어들 집중해서 읽지 않습니다. 중요하다고 생각하는 단어에만 집중을 하고 나머지는 그냥 읽습니다. 이 방법이 문맥을 파악하는 핵심입니다. 이러한 방식을 딥러닝 모델에 적용한 것이 'Attention'메커니즘입니다. 위의 그림은 한/영 번역에서의 Attention을 나타내고 있습니다. 보시다시피 영어 'cafe'와 한국어 '카페'가 강한 Attention 상관관계에 있습니다. 이에 비해 다른 단어들과는 Attention이 약합니다.
Attention 모델의 구조
Encoder와 Decoder
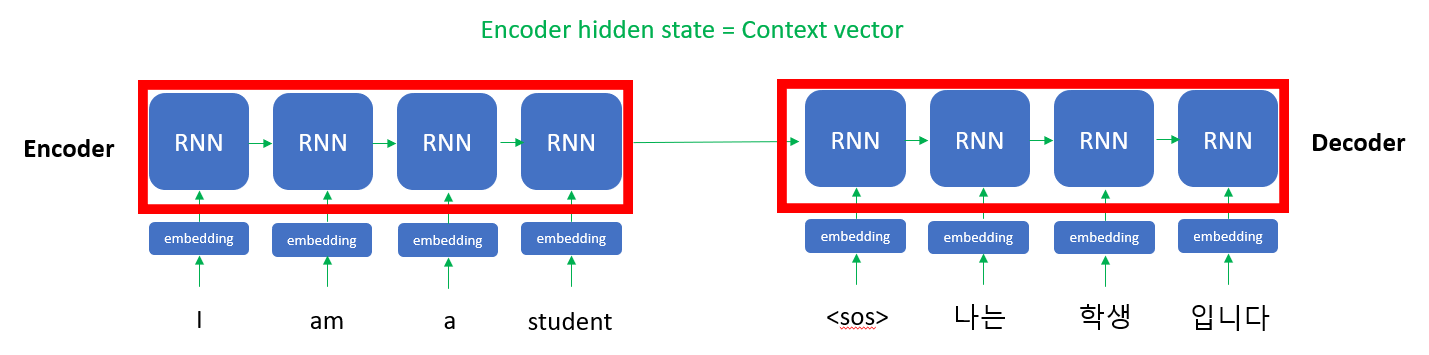
지금부터는 Attention 모델의 구조에 대해 알아보도록 하겠습니다. Attention을 설명하기에 앞서 Encoder와 Decoder에 대해 설명하도록 하겠습니다. 위의 영/한 번역의 예시를 이용해 이를 설명하겠습니다. 대부분의 자연어 모델은 Encoder와 Decoder로 구성이 되어있습니다. Encoder는 입력으로 input data를 받아 압축 데이터(context vector)로 변환 및 출력해주는 역할을 합니다. Decoder는 반대로 압축 데이터(context vector)를 입력 받아 output data를 출력해줍니다. 이는 우리가 사용하는 전화기의 원리와 동일한데, 이렇게 해주는 이유는 정보를 압축하므로써 연산량을 최소화하기 위해서입니다. 위 그림에서 보다시피 문맥 벡터는 Encoder의 마지막 RNN 셀에서만 나오므로 그 전 RNN셀들의 반영이 되지 않습니다. 이렇게 문맥 벡터(context vector)를 사용하면 연산량이 줄어든다는 장점이 있지만 정보의 손실이 발생하는 문제점 역시 발생하게 됩니다. 이러한 정보 손실 문제를 해결하기 위해 'Attention'이라는 개념이 도입됐습니다.


위는 RNN의 구조를 도식화한 것입니다. 보시다시피 output으로 hidden state가 나오는 것을 알 수 있습니다. 이 때문에 위의 Encoder and Decoder 구조에서 각각의 out이 hidden state의 형태로 출력됩니다. 유의할 점은 Encoder의 경우 모든 RNN 셀의 hidden states들을 사용하는 반면, Decoder의 경우 현재 RNN셀의 hidden state만을 사용합니다. 그 이유는 맨 위의 그림 '한/영 번역의 Attention'에서 보다시피 Target seqence의 한 단어와 Source seqence의 모든 단어의 Attention 상관관계를 비교하기 때문입니다. 여기서 hidden state는 압축된 문맥으로 해석할 수 있습니다.
- Decoder hidden state: Target seqence의 문맥
- Encoder hidden states: Source seqence의 문맥(모든 문맥을 활용하겠다.)
Attention Score

이제 위에서 구한 Encoder hidden states와 Decoder hidden state을 이용해 Attention score를 구해줍니다. hidden state는 행렬입니다. 때문에 위의 그림과 같이 Encoder hidden states들과 전치한 Decoder hidden state를 내적(dot product)해주면 상수 값이 나오게 됩니다. 이 상수값은 Encoder의 RNN셀의 수만큼 나오게 됩니다. 위의 경우 score1 ~ score4까지 4개가 나옵니다. 이 score들을 Attention score라고 부릅니다.
Attention Value

앞에서 구한 Attention score들을 softmax 활성 함수(activation function)에 대입하여 Attention distribution을 만들어줍니다. 이렇게 하는 이유는 각 score들의 중요도를 상대적으로 보기 쉽게 하기 위해서입니다. softmax함수는 어떤 변수를 0 ~ 1 사이의 값으로 만들어주는데, 이를 다른 말로 하면 확률화 해준다는 것입니다. 즉 Attention score들을 확률분포로 변환한다고 이해하시면 됩니다. 그다음 Encoder hidden states들을 방금 구한 Attention distribution에 곱하여 합해주어 Attention value 행렬을 만들어줍니다. 즉 각 문맥들(hidden states)의 중요도(Attention score)를 반영하여 최종 문맥(Attention value)을 구한다고 생각하면 됩니다.

마지막으로 Decoder의 문맥을 추가해주기 위해 Decoder hidden state를 Attention value아래 쌓아 줍니다. 이 과정을 'concatenate'라고 합니다. 추가적으로 성능을 향상하기 위해 tanh, softmax 활성 함수를 이용해 학습을 시키면 최종적인 출력 'y'가 나오게 됩니다.

오늘 배운 내용에 대해 잘 이해가 안되신다거나, 부가적인 설명이 필요하시면, 아래 제 유튜브 영상을 참고하시면 됩니다.
정성스럽게 영상을 제작 했으니 꼭 한번 들러주세요 :)
https://www.youtube.com/watch?v=SR4F6WMqZ0s
정리
- Attention: 모델의 성능 향상을 위해 문맥에 따라 집중할 단어를 결정하는 방식
- Decoder hidden state: Target seqence의 문맥
- Encoder hidden states: Source seqence의 문맥(모든 문맥을 활용하겠다.)
1. Encoder hidden states들과 Decoder hidden state를 내적(dot product)하여 Attention score계산
2. Attention score에 softmax함수를 취하고 이를 다시 Encoder hidden states들과 곱한 다음 이를 합하여 Attention value계산
3. Attention value 행렬에 Decoder hidden state 행렬을 쌓아 올리고(concatenate) tanh, softmax함수를 통해 학습시키다.
그 밖에 Transformer 메커니즘이 궁금하신 분들은 아래 글들을 참고하시기 바랍니다.
https://codingopera.tistory.com/43
4-1. Transformer(Self Attention) [초등학생도 이해하는 자연어처리]
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진
codingopera.tistory.com
https://codingopera.tistory.com/44
4-2. Transformer(Multi-head Attention) [초등학생도 이해하는 자연어처리]
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진
codingopera.tistory.com
추가적으로 제가 AI 학습 관련 오픈 카카오톡방을 만들었습니다. AI와 코딩 학습에 목말라 있으신분들이라면 누구나 들어와서 즐겁게 맘껏 정보공유와 AI 공부하시면 될 것 같습니다. 링크는 다음과 같이니 꼭 한번 참석 및 홍보 부탁드리겠습니다.
https://open.kakao.com/o/ggxse9sg
인공지능/AI/코딩 공부방(코딩오페라)
인공지능/AI/코딩 공부방
open.kakao.com
추가적으로 Transformer에 대해 좀더 자세히 알고싶으신 분들은 아래 제 유튜브 영상을 참고하시면 됩니다.
정성스럽게 영상을 제작 했으니 꼭 한번 들러주세요 :)
[Transformer의 Embedding과 Positional Encoding]
https://www.youtube.com/watch?v=-z2oBUZfL2o
[Transformer의 Residual Connection과 Layer Normalization]
https://www.youtube.com/watch?v=eq4zlaqaDvI
Transformer에 대해 python code가 궁금하신 분들은 다음 글이 많은 도움이 되실겁니다!
https://codingopera.tistory.com/74
4-4. Harvard Transformer Code 리뷰 [초등학생도 이해하는 자연어처리]
안녕하세요 '코딩 오페라'입니다.현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진짜 핵심 내용을 쉽게 설명하는 것을
codingopera.tistory.com
지금 까지 저희는 'Attention'에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이었습니다. 감사합니다.
'자연어처리(NLP)' 카테고리의 다른 글
| 4-2. Transformer(Multi-head Attention) [초등학생도 이해하는 자연어처리] (2) | 2022.12.14 |
|---|---|
| 4-1. Transformer(Self Attention) [초등학생도 이해하는 자연어처리] (12) | 2022.12.13 |
| 2-1. BOW(Bag of Words)기반 'TF-IDF' [초등학생도 이해하는 자연어처리] (0) | 2022.10.24 |
| 2. BOW(Bag of Words)기반 '카운트 벡터(Count Vector)' [초등학생도 이해하는 자연어처리] (0) | 2022.10.18 |
| 1. 토큰화 [초등학생도 이해하는 자연어처리] (0) | 2022.10.18 |



