안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다.
오늘 알아볼 내용은 '살사(SARSA)'입니다.
저의 경우 2016년 알파고와 이세돌의 바둑 대결로 인해 인공지능에 관심이 많이 생기기 시작했고 이후 구글의 딥마인드 팀에서 발표한 DQN논문 특히 아타리사의 '브레이트 아웃' 게임을 하는 것을 보고 많은 감명을 받아 '강화 학습'이라는 학문에 많은 관심을 갖게 되었습니다. 그래서 오늘부터는 강화 학습에 대해 차분히 정리를 해보도록 하겠습니다.
저는 '파이썬과 케라스로 배우는 강화 학습'이라는 책을 읽으면서 독학을 하였습니다. 이 글은 이 책을 참고하여 제작합니다.(광고 아닙니다!!)
https://codingopera.tistory.com/24
4. [강화학습] 몬테카를로 예측(Monte-Carlo Prediction)
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 오늘 알아볼 내용은 '몬테카를로 예측(Monte-Carlo Prediction)'입니다. 저의 경우 2016년 알파고와 이세돌의 바둑 대결로
codingopera.tistory.com
우리는 저번 시간에 시간차 예측(Temporal-Difference Approximation)에 대해 알아보았습니다. 잘 모르시는 분들은 위의 링크를 참고하시기 바랍니다. 간단히 다시 설명하자면 '시간차 예측'이란 타임 스텝마다 가치 함수를 현재 상태에 대해서만 업데이트합니다. 오늘은 이를 이용한 '시간차 제어(Temporal-Difference Control)'에 대해 알아보도록 하겠습니다.
1. SARSA
우선 가치함수를 이용하려면 환경을 알아야 합니다. 그러나 큐 함수를 이용하면 model-free 즉 환경을 모르는 상태에서도 학습이 가능합니다. 그 이유는 큐 함수는 상태와 행동을 포함하고 있기 때문입니다. 따라서 시간차 예측 함수에 큐함수를 대입하면 아래와 같은 식이 나옵니다.


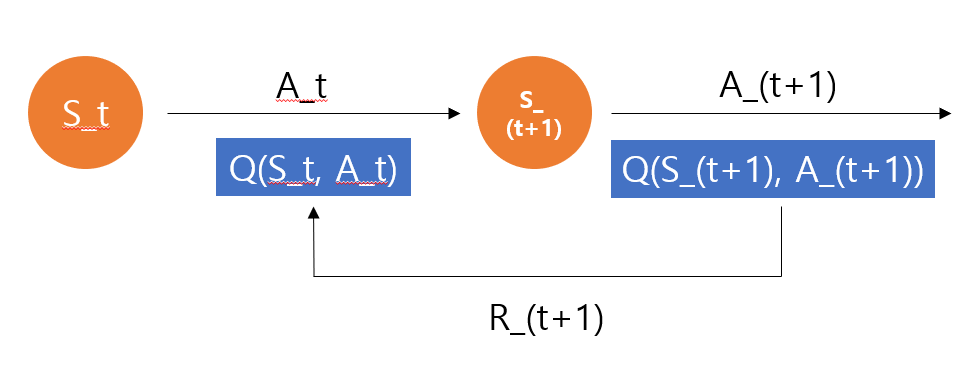
위 식을 자세히 보면 현재상태, 행동, 보상, 다음 상태, 행동을 통해 큐 함수를 업데이트하고 있습니다. 때문에 이는 위에서 처럼 SARSA샘플을 통해 학습을 하게되고 앞 대문자를 따서 'SARSA'라고 부릅니다. 이를 코드로 나타내면 아래와 같습니다. 수식과 비교해보시기 바랍니다.
# <s, a, r, s', a'>의 샘플로부터 큐함수를 업데이트
def learn(self, state, action, reward, next_state, next_action):
current_q = self.q_table[state][action]
next_state_q = self.q_table[next_state][next_action]
new_q = (current_q + self.learning_rate *
(reward + self.discount_factor * next_state_q - current_q))
self.q_table[state][action] = new_q
2. Epsilon 탐욕 정책(Epsilon Greedy Policy)
강화학습의 오랜 문제 중 하나는 exploration과 exploitation 중 무엇이냐?입니다. 여기서 exploration은 탐험을, exploitation은 기존 학습을 우선시합니다. 이를 중용할 수 있는 방법이 'Epsilon 탐욕 정책(Epsilon Greedy Policy)'입니다. 원리는 간단합니다. 0 ~ 1사이값중 하나를 Epsilon으로 설정하고 다시 0 ~ 1 사이 수를 랜덤 하게 뽑았을 때 Epsilon 보다 작으면 exploration을, 아니면 exploitation을 선택하게 됩니다. 이를 코드로 나타내면 아래와 같습니다. 수식과 비교해보시기 바랍니다.
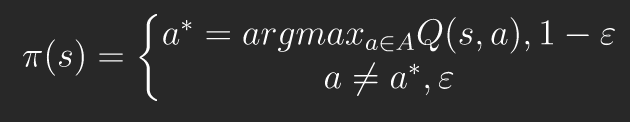
# 입실론 탐욕 정책에 따라서 행동을 반환
def get_action(self, state):
if np.random.rand() < self.epsilon:
# 무작위 행동 반환
action = np.random.choice(self.actions)
else:
# 큐함수에 따른 행동 반환
state_action = self.q_table[state]
action = self.arg_max(state_action)
return action
아래 제 깃허브에 들어가시면 grid-world라는 게임의 환경과 sarsa agent 전체 코드를 볼 수 있습니다.
https://github.com/CodingOpera/RL/tree/main/4-sarsa
GitHub - CodingOpera/RL
Contribute to CodingOpera/RL development by creating an account on GitHub.
github.com
지금 까지 저희는 '살사(SARSA)'에 대해 알아보았습니다. 도움이 되셨나요? 만약 되셨다면 구독 및 좋아요로 표현해 주시면 정말 많은 힘이 됩니다. 궁금한 사항 혹은 앞으로 다루어 주었으면 좋을 주제가 있으시면 댓글 남겨주시면 감사하겠습니다. 저는 '코딩 오페라'의 'Master.M'이었습니다. 감사합니다.
'강화학습' 카테고리의 다른 글
| 7. [강화학습] 딥살사(Deep SARSA) (0) | 2022.04.04 |
|---|---|
| 6. [강화학습] 큐러닝(Q-learning) (0) | 2022.03.25 |
| 4. [강화학습] 몬테카를로 예측(Monte-Carlo Prediction) (0) | 2022.03.24 |
| 3. 강화학습 동적 프로그래밍(Dynamic Programming) (0) | 2022.03.24 |
| 2. 강화학습 MDP(Markov Decision Process) (0) | 2022.03.21 |



